AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTSection by Andrei Frumusanu
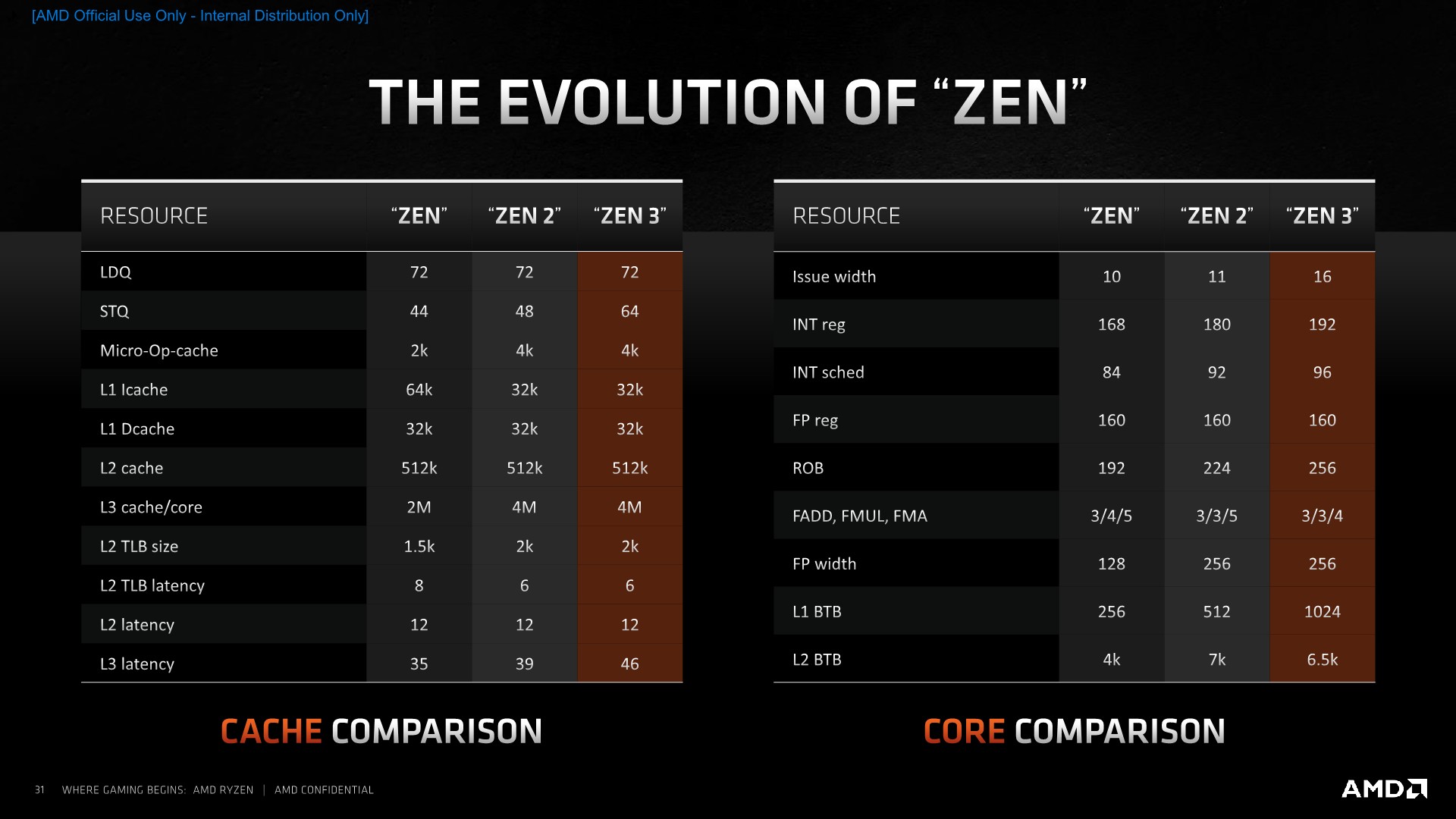
The New Zen 3 Core: Load/Store and a Massive L3 Cache
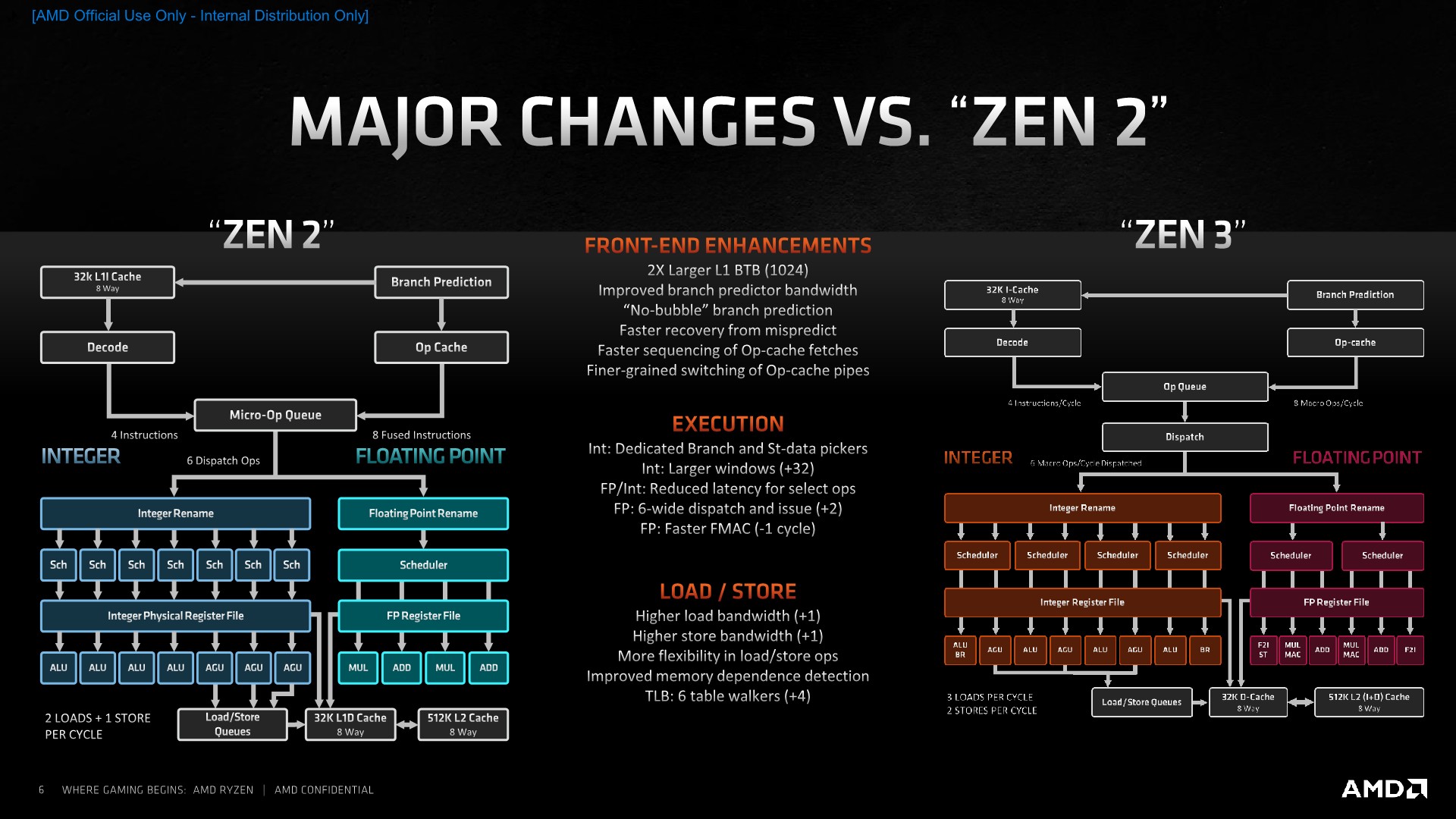
Although Zen3’s execution units on paper don’t actually provide more computational throughput than Zen2, the rebalancing of the units and the offloading of some of the shared execution capabilities onto dedicated units, such as the new branch port and the F2I ports on the FP side of the core, means that the core does have more actual achieved computational utilisation per cycle. To be able to make sure that memory isn’t a bottleneck, AMD has notably improved the load/store part of the design, introducing some larger changes allowing for some greatly improved memory-side capabilities of the design.
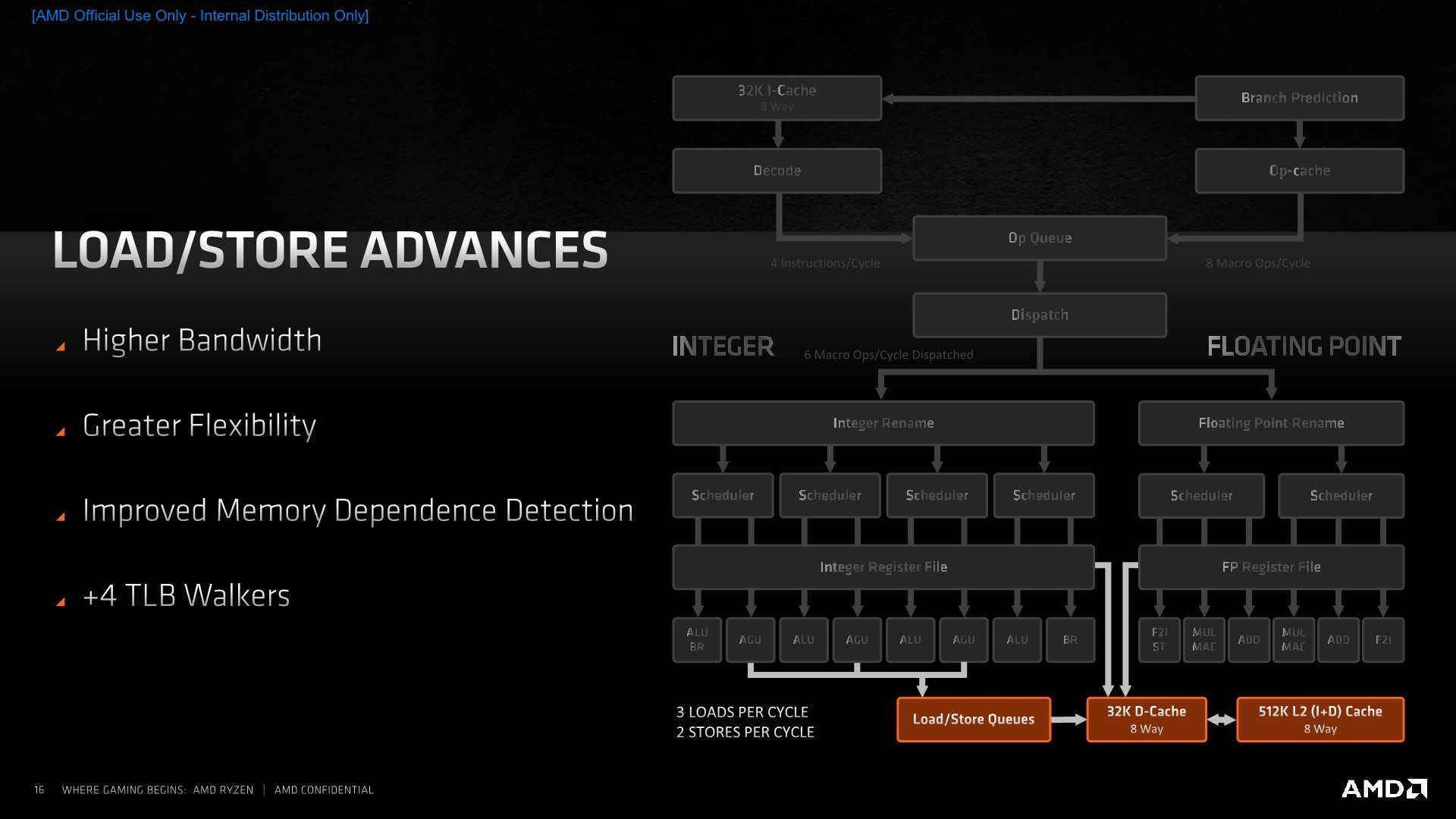
The core now has a higher bandwidth ability thanks to an additional load and store unit, with the total amount of loads and stores per cycle now ending up at 3 and 2. AMD has improved the load to store forwarding to be ablet to better manage the dataflow through the L/S units.
An interesting large upgrade is the inclusion of 4 additional table walkers on top of the 2 existing ones, meaning the Zen3 cores has a total of 6 table walkers. Table-walkers are usually the bottleneck for memory accesses which miss the L2 TLB, and having a greater number of them means that in bursts of memory accesses which miss the TLB, the core can resolve and fetch such parallel access much faster than if it had to rely on one or two table walkers which would have to serially fulfil the page walk requests. In this regard, the new Zen3 microarchitecture should do significantly better in workloads with high memory sparsity, meaning workloads which have a lot of spread out memory accesses across large memory regions.
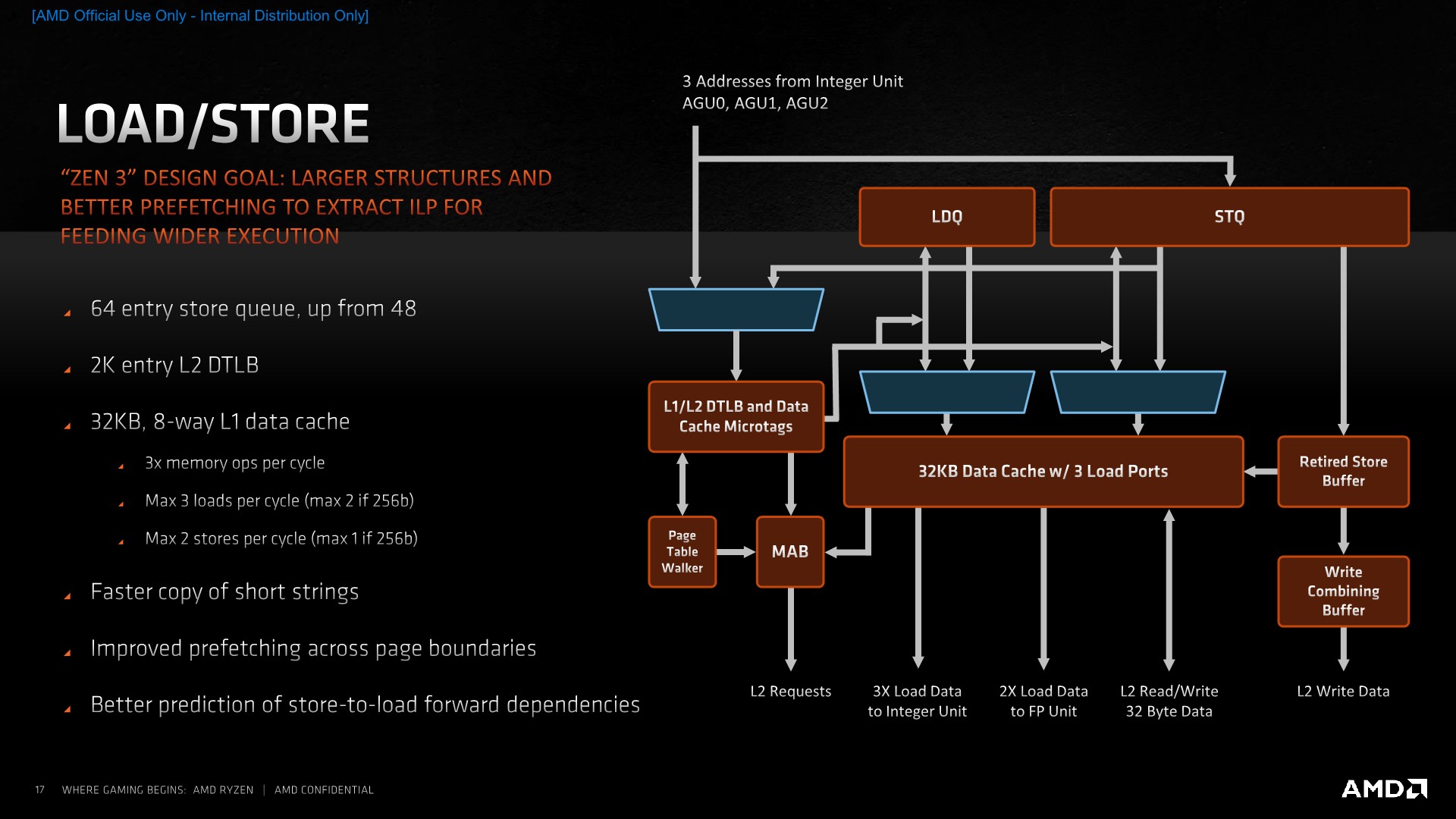
On the actual load/store units, AMD has increased the depth of the store queue from 48 entries to 64. Oddly enough, the load queue has remained at 44 entries even though the core has 50% higher load capabilities. AMD counts this up to 72 by counting the 28-entry address generation queue.
The L2 DTLB has also remained at 2K entries which is interesting given that this would now only cover 1/4th of the L3 that a single core sees. AMD explains that this is simply a balance between the given performance improvement and the actual implementation complexity – reminding us that particularly in the enterprise market there’s the option to use memory pages larger than your usual 4K size that are the default for consumer systems.
The L1 data cache structure has remained the same in terms of its size, still 32KB and 8-way associative, but now seeing an increase in access concurrency thanks to the 3x loads per cycle that the integer units are able to request. It doesn’t actually change the peak bandwidth of the cache as integer accesses can only be 64b for a total of 192b per cycle when using 3 concurrent loads – the peak bandwidth is still only achieved through 2 256b loads coming from the FP/SIMD pipelines. Stores similarly have been doubled in terms of concurrent operations per cycle, but only on the integer side with 2 64b stores, as the FP/SIMD pipes still peak out at 1 256b store per cycle.
REP MOVS instructions have seen improvements in terms of its efficiencies for shorter buffer sizes. This means that in contrast to past microarchitectures which might have seen better throughput with other copy algorithms, on Zen3 REP MOVS will see optimal performance no matter how big or small the buffer size being copied is.
AMD has also improved their prefetchers, saying that now patterns which cross page boundaries are better detected and predicted. I’ve noted also that the general prefetcher behaviours have dramatically changed, with some patterns, such as adjacent cache lines being pulled into L1, something which is very aggressive, and also more relaxed behaviour, such as some of our custom pattern no longer being as aggressively picked up by then new prefetchers.
AMD says that the store-to-load forwarding prediction is important to the architecture and that there’s some new technology where the core is now more capable of detecting dependencies in the pipeline and forwarding earlier, getting the data to instructions which need them in time.
A Big Fat 32MB L3 Cache
Moving out from the individual cores, we come to the brand-new 32MB L3 cache which is a cornerstone characteristic of the new Zen3 microarchitecture and the new Ryzen 5000 CCD:

The big change here is of a topological nature, as AMD does away with the 4-core CCX which had been previously used as the unified core cluster block for Zen/Zen+/Zen2. Instead of having to divide a chiplet’s total cache capacity into two blocks of 4 and 4 cores, the new unified L3 aggregates the previously laid out SRAM amount into a single large 32MB pool spanning 8 cache slices and servicing 8 cores.
Achieving this larger 32MB L3 cache didn’t come without compromises as latencies have gone up by roughly 7 cycles to 46 cycles total. We asked AMD about the topology of the new cache but they wouldn’t comment on it besides stating that it’s still an address-hash based system across the 8 cache slices, with a flat memory latency across the depth of the cache, from the view of a single core.
One thing that AMD wasn’t able to scale up with the new L3 cache is cache bandwidth – here the new L3 actually features the same interface widths as on Zen2, and total aggregate bandwidth across all the cores peaks out at the same number as on the previous generation. The thing is now, the cache serves double the cores, so it means that the per-core bandwidth has halved this generation. AMD explains is that also scaling up the bandwidth would have incurred further compromises, particularly on the power side of things. In effect this means that the aggregate L3 bandwidth on a CCD, disregarding clock speed improvements, will be half of that of that of a Zen2/Ryzen 3000 CCD with two CCX’s (Essentially two separate L3’s).
The net win of the new structure from greatly improved cache hit rates for application with larger memory pressures, taking advantage of the full 32MB L3, as well as workloads which make use of heavy synchronisation and core-to-core data transfers: Whereas in previous generations two cores in different CCX’s on the same die would have to route traffic through the IOD, this on-die penalty is completely eliminated on Zen3, and all cores within the new CCD have full and low-latency communication to each other through the new L3.

Viewing the whole cache hierarchy on the new Zen3 design, we see a somewhat familiar picture. The L2’s have remained unchanged at 512KB and a 12-cycle access latency, with the memory interfaces from the L1D to through to the L3 coming in at 32B/cycle both in reads and writes.
The L3 continues to maintain shadow tags of the cores’ L2 contents – so if a cache line is requested by one core and resides on another core in the new core complex, the L3 will know from which core to fetch that line back from.
In terms of parallelism, there can be up to 64 outstanding misses from the L2 to the L3, per core. Memory requests from the L3 to DRAM hit a 192 outstanding miss limit – which actually might be a bit low in scenarios where there’s a lot of cores accessing memory at the same time. This is a doubling from the 96 outstanding misses per L3 on Zen2, so the misses per core ratio here at least hasn’t changed.
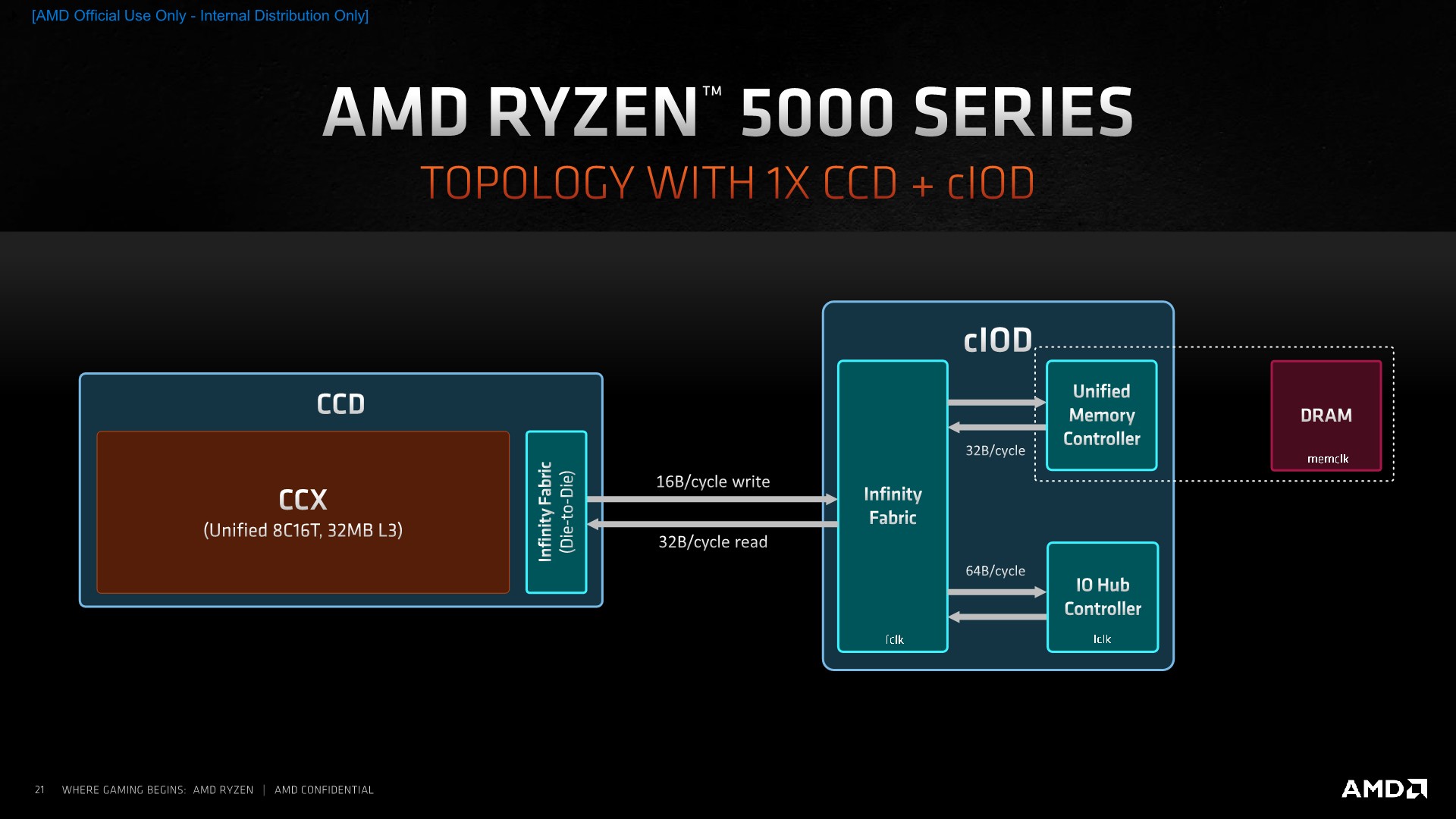

In terms of the packaging topology, because the new Ryzen 5000 series are using the same IOD as the Ryzen 3000 series, we don’t actually see any change in the overall structure of the design. We can either have SKUs with only a single chiplet, such as the new Ryzen 5 5600X or Ryzen 7 5800X, or deploy two chiplets, such as the Ryzen 9 5900X or Ryzen 9 5950X.
The bandwidth between the CCD and the IOD remains the same between generations, with 16B/cycle writes from the CCD to the IOD, and 32B/cycle reads in the opposite direction. Infinity fabric speed is the determining factor for the resulting bandwidth here, which AMD still recommends to be coupled 1:1 with DRAM frequency for the best memory latency, at least until around DDR4-3600, and slightly above for overclockers.
While we’ll be covering the end-performance and actual IPC improvements of Zen3 in the following pages, the first impressions based on AMD’s microarchitectural disclosures are that the new design is indeed a larger-than-average effort in the company’s CPU roadmap.
AMD calls Zen3 a ground-up redesign or even a clean-sheet design. Whilst that seems a quite lofty description of the new microarchitecture, it’s true that at least the architects have touched a lot of aspects of the design, even if at the end a lot of the structures and actual overall width of the core, especially on the front-end, hasn’t actually changed all that much from Zen2.
My view of what Zen3 is, is that it’s a rebuild of the previous generation, with AMD taking lessons from the past implementation and improving and refining the overall broader design. When asked about future potential for widening the core, similarly to some of the current competing microarchitectures out there, AMD’s Mike Clarke admitted that at some point they will have to do that to make sure they don’t fall behind in performance, and that they are already working on another future clean-sheet redesign. For the time being, Zen3 was the right choice in terms balancing out performance, efficiency, time-to-market, as well as considering that this generation actually didn’t have a large process node uplift (Which by the way, will be a rarer and increasingly unreliable vector for improving performance in the future).
I do hope that these designs come in a timely fashion with impressive changes, as the competition from the Arm side is definitely heating up, with designs such as the Cortex-X1 or the Neoverse-V1 appearing to be more than a match for lower-clocked Zen3 designs (such as in the server/enterprise space). On the consumer side of things, AMD appears to be currently unrivalled, although we’ll be keeping an eye open for the upcoming Apple silicon.








339 Comments
View All Comments
Hifihedgehog - Thursday, November 5, 2020 - link
Bloodbathgagegfg - Thursday, November 5, 2020 - link
Intel is preaching Moore's Law, AMD is executing it.FoRealz - Thursday, November 5, 2020 - link
Wow 5600x beating the 5900x in almost everything?Hul8 - Thursday, November 5, 2020 - link
Regarding "Why Does AMD Not Promote 5.0 GHz?":I'm sure AMD would rather talk to journalists about why some of their CPUs boosts +150MHz beyond the advertized boost frequency, and whether that's normal, than about many of the CPUs not reaching the advertized number... They learned that lesson.
haukionkannel - Friday, November 6, 2020 - link
Indeed! They did market last time that some golden samples will boost up to xxx... and the peoples reaction was really Angry! Now under advertising, ower delivering gives them perks instead, so yeah They Are learning!Because in the end, independent reviews will reveal the real speed eventually, so it does not hurt at all under advertise, because reviews will do all the advertisement amd needs!
Spunjji - Sunday, November 8, 2020 - link
100%poohbear - Thursday, November 5, 2020 - link
Doesn't like much of a difference between the mainstream 5800x and the 10700k. It'll boil down to price when choosing between them. TBH i'm a bit disappointed as i was expecting a trouncing of Intel by AMD, but now we see AMD is just matching Intel, which is great, but since the 5xxx AMD CPUs are matching Intel's in price, we haven't really reached new heights of performance or anything. But i guess the silver lining is competition is back, and now performance matters again.WaltC - Friday, November 6, 2020 - link
In some games, which is what I assume you are talking about since AMD walks away with almost all productivity software, AMD holds a lead of 30% +. Secondly, when game-engine optimization for Zen2/3 begins to mature and become widespread, AMD should walk away with most of it. It's interesting that in the titles where the most expensive Intel CPUs keep pace with the 5600X in terms of frame rates, the game engines were heavily optimized for Intel architectures.haukionkannel - Friday, November 6, 2020 - link
Well Intel did cut prices a lot to get even with amd, so amd has done its job in that part. Intel still have cpus that needs even more price cuts!But that is how market works. If Intel wants to compete with amd It has to do it with prices! And in the end it means you will get both companies products about the same price vs performance range! The point is that because of amd Intel has to compete with prices and as long as amd keep making these advancements Intel has to react and that means that there is competition and neither company can get too creedy! If one company has huge lead... it means higher prices. Now both companies has good products, the market will take of the prising!
duploxxx - Saturday, November 7, 2020 - link
you are smoking right?If you want better game performance you take the 5600X its faster everywhere vs 10700k and cheaper and on top very close performance on productivity not to mention way lower power consumption.
if you want more productivity and gaming you spend just a bit more and you get both. And still lower power consumption.
There are 0 reasons to buy an Intel cpu right now in this price range. THey will need to drop at least with 50-100$ to stay competitive. Not to mention there boards that lack PCIe-4.
lets see what smart memory does soon with ATI combo and there will even be less reasons to buy the Intel parts.