Google's Tensor inside of Pixel 6, Pixel 6 Pro: A Look into Performance & Efficiency
by Andrei Frumusanu on November 2, 2021 8:00 AM EST- Posted in
- Mobile
- Smartphones
- SoCs
- Pixel 6
- Pixel 6 Pro
- Google Tensor
Memory Subsystem & Latency
Usually, the first concern of a SoC design, is that it requires that it performs well in terms of its data fabric and properly giving its IP blocks access to the caches and DRAM of the system within good latency metrics, as latency, especially on the CPU side, is directly proportional to the end-result performance under many workloads.
The Google Tensor, is both similar, but different to the Exynos chips in this regard. Google does however fundamentally change how the internal fabric of the chip is set up in terms of various buses and interconnects, so we do expect some differences.
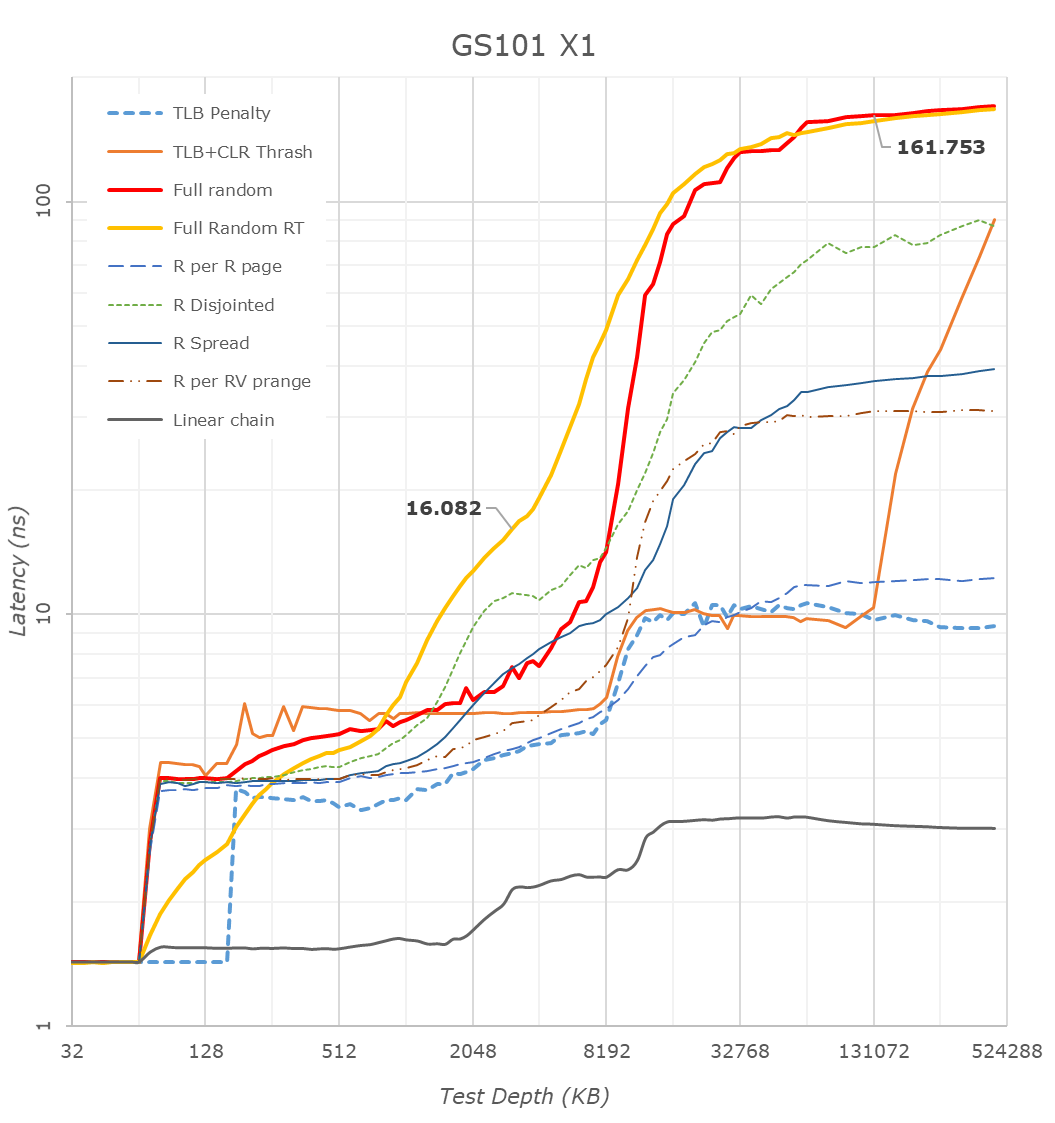
First off, we have to mention that many of the latency patterns here are still quite a broken due to the new Arm temporal prefetchers that were introduced with the Cortex-X1 and A78 series CPUs – please just pay attention to the orange “Full Random RT” curve which bypasses these.
There’s a couple of things to see here, let’s start at the CPU side, where we see the X1 cores of the Tensor chip being configured with 1MB of L2, which comes in contrast with the smaller 512KB of the Exynos 2100, but in line with what we see on the Snapdragon 888.
The second thing to note, is that it looks like the Tensor’s DRAM latency isn’t good, and showcases a considerable regression compared to the Exynos 2100, which in turn was quite worse off than the Snapdragon 888. While the measurements are correct in what they’re measuring, the problem is a bit more complex in the way that Google is operating the memory controllers on the Google Tensor. For the CPUs, Google is tying the MCs and DRAM speed based on performance counters of the CPUs and the actual workload IPC as well as memory stall % of the cores, which is different to the way Samsung runs things which are more transactional utilisation rate of the memory controllers. I’m not sure of the high memory latency figures of the CPUs are caused by this, or rather by simply having a higher latency fabric within the SoC as I wasn’t able to confirm the runtime operational frequencies of the memory during the tests on this unrooted device. However, it’s a topic which we’ll see brought up a few more times in the next few pages, especially on the CPU performance evaluation of things.
The Cortex-A76 view of things looks more normal in terms of latencies as things don’t get impacted by the temporal prefetchers, still, the latencies here are significantly higher than on competitor SoCs, on all patterns.
What I found weird, was that the L3 latencies of the Tensor SoC also look to be quite high, above that of the Exynos 2100 and Snapdragon 888 by quite a noticeable margin. I noted that one weird thing about the Tensor SoC, is that Google didn’t give the DSU and the L3 cache of the CPU cluster a dedicated clock plane, rather tying it to the frequency of the Cortex-A55 cores. The odd thing here is that, even if the X1 or A76 cores are under full load, the A55 cores as well as the L3 are still running at lower frequencies. The same scenario on the Exynos or Snapdragon chip would raise the frequency of the L3. This behaviour and aspect of the chip can be confirmed by running at dummy load on the Cortex-A55 cores in order to drive the L3 higher, which improves the figures on both the X1 and A76 cores.
The system level cache is visible in the latency hump starting at around 11-13MB (1MB L2 + 4MB L3 + 8MB SLC). I’m not showing it in the graphs here, but memory bandwidth on normal accesses on the Google chip is also slower than on the Exynos, but I think I do see more fabric bandwidth when doing things such as modifying individual cache lines – one of the reasons I think the SLC architecture is different than what’s on the Exynos 2100.
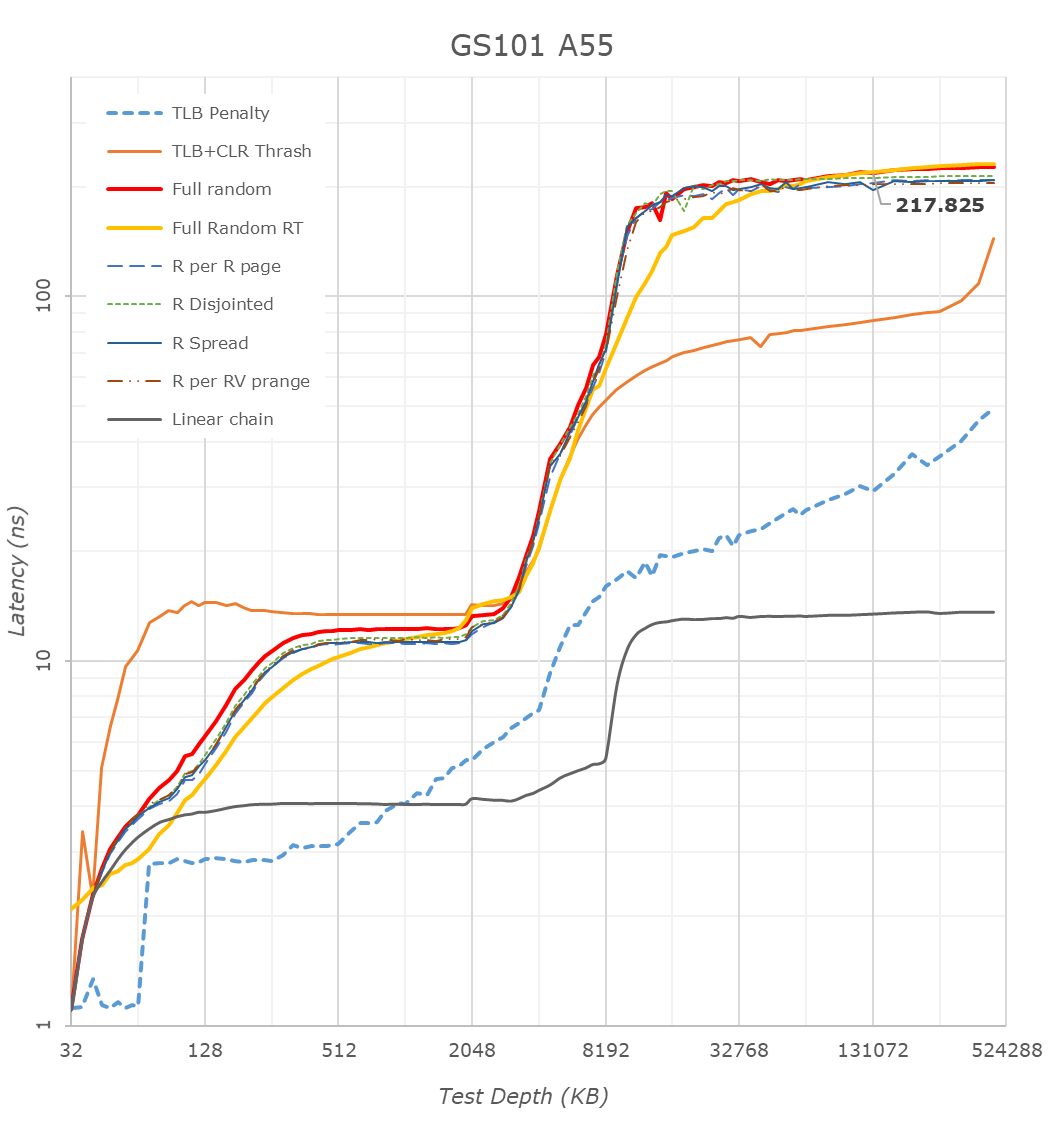
The A55 cores on the Google Tensor have 128KB of L2 cache. What’s interesting here is that because the L3 is on the same clock plane as the Cortex-A55 cores, and it runs at the same higher frequencies, is that the Tensor’s A55s have the lowest L3 latencies of the all the SoCs, as they do without an asynchronous clock bridge between the blocks. Like on the Exynos, there’s some sort of increase at 2MB, something we don’t see on the Snapdragon 888, and I think is related to how the L3 is implemented on the chips.
Overall, the Tensor SoC is quite different here in how it’s operated, and there’s some key behaviours that we’ll have to keep in mind for the performance evaluation part.








108 Comments
View All Comments
jaju123 - Tuesday, November 2, 2021 - link
Thanks Andrei, using the P6 Pro right now and it is remarkably smooth in terms of general UI regardless of the benchmark scores etc., in comparison to other phones. I suspect the scheduling and UI rendering side of things are contributing here. Very much looking forward to the camera review!jiffylube1024 - Wednesday, November 3, 2021 - link
Same experience here on a P6 regular.I went from an S20 (regular) to the P6 pro. Wife has the S21 regular.
My experience so far:
UI is insanely fast and smooth on the P6. Everything is buttery smooth, no lag ever. It's a joy to use. The S20 is a very fast phone, but it did have the very occasional hiccup when switching between many different apps. So far, this hasn't happened on the Pixel 6 at all.
The S20 had nicer hardware overall, and the hand size was perfect. S20 screen gets a bit brighter, was a tiny bit sharper, and auto-adjust brightness was basically perfect on the S20, it's a little bit imperfect on the P6 (occasionally goes up or down in low light for no reason).
All in all, I'm very happy with the Pixel 6. If the Pixel 7 comes in a 6"-6.2" version next year, I may have to switch again, though!
Kangal - Wednesday, November 3, 2021 - link
That's because it is running a mostly Stock OS. Google severely limits background tasks when in use, and prioritises touch input... as opposed to say Samsung, which starts off slower and raises frequency in steps, whilst continuing background tasks. This slows the experience, but can boost efficiency, depending on the user.Now, the Cortex-A76 is actually not bad. It's a great chip, as it's quiet fast while being efficient. It requires less area and density compared to the A77 and A78. So Google didn't make a mistake here. By going for the A76, they were able to upgrade to have two Cortex-X1 cores. It is a design choice. Another design choice could be 3x X1 and 5x A55, cutting out the Middle-cores for a more simpler design. Or you could potentially have 4x A78 and 4x A55, and have the A78 cores clock higher, for better sustained performance than X1. These are all different design choices, one can be better than another, but it depends on the circumstances.
Kangal - Wednesday, November 3, 2021 - link
I just want to add my viewpoint on the performance and efficiency of this chipset/phone.AI/ML/NPU/TPU Benchmark: GeekBench ML 0.5
This looks like the most accurate representation. The iPhone 13 has an impressive AI performance because their SDK is better fleshed out, their software is coded more natively, and the SoC has pretty impressive specs Cache, CPU, GPU to help with such tasks. The GS101 wins in the Android ecosystem by a wide margin, followed by QSD 888, MediaTek Dimensity, then lastly Exynos. We can see the proper AI chart here: https://images.anandtech.com/graphs/graph17032/126...
GPU Benchmark: GFxBench Aztec Ruins High (Sustained)
This looks like the most accurate representation. Again Apple flexes its lead with its optimised software and cutting-edge hardware. Larger phones with better cooling manage to score higher, and giving preference to Qualcomm's mature drivers, followed by Huawei's node advantage, then the mediocre attempts by Exynos which is tied for the last spot with the GS101. We can see the proper GPU chart here: https://images.anandtech.com/graphs/graph17032/101...
CPU Multithread Benchmark: GeekBench 5 (crude Single/Multithread)
In the multi-thread test, it shows how sacrificing the middle cores has affected the total score, where it helps to boost the performance of the first 1-2 threads. So at least that design choice is captured. We can see the proper Multithread CPU chart here: https://images.anandtech.com/graphs/graph16983/116...
CPU Single-core Benchmark: SPEC 2017 (fp scores)
The SPEC test is more nuanced. We've established that Anandtech has made huge blunders here. Instead of reporting the Power Draw (watts) of the chipset, they instead try to calculate Energy Consumed (joules) by estimating it crudely. It is for that reason, we get some very inconsistent and wrong data. Such as Apple's Efficiency cores using less power than a Cortex-A53, yet producing scores in line with the Cortex-A78.
So instead, we will focus on the fp-scores instead of the int-scores, since this actually scales better from chipset to chipset. And we will focus on the Power Draw figures, to get the proper data. In particular, the tests of 526, 544, and 511 are quite revealing. We can see the proper CPU chart here:
https://images.anandtech.com/doci/16983/SPECfp-pow...
As a summary of the raw data, here:
Chipset-CoreType: Performance Value / Watts Recorded = Efficiency Score
Apple A14-E: 2.54 / 0.42 = 6.05
Apple A15-E: 3.03 / 0.52 = 5.83
Dim 1200-A55: 0.71 / 0.22 = 3.23
QSD 888-A55: 0.85 / 0.30 = 2.83
Exy 990-A55: 0.84 / 0.50 = 1.68 (? too low! Watts probably not recorded correctly)
Exy 2100-A55: 0.94 / 0.57 = 1.65 (? too low! Watts probably not recorded correctly)
GS 101-A55: 0.88 / 0.59 = 1.49 (? too low! Watts probably not recorded correctly)
Apple A15-P: 10.15 / 4.77 = 2.13
QSD 870-A77: 5.76 / 2.77 = 2.08
Apple A14-P: 8.95 / 4.72 = 1.90
QSD 888-X1: 6.28 / 3.48 = 1.80
GS 101-X1: 6.17 / 3.51 = 1.76
Dim 1200-A78: 4.71 / 2.94 = 1.60
Exy 2100-X1: 6.23 / 3.97 = 1.57
Exy 990-M5: 4.87 / 3.92 = 1.24
Andrei Frumusanu - Thursday, November 4, 2021 - link
> We've established that Anandtech has made huge blunders here. Instead of reporting the Power Draw (watts) of the chipset, they instead try to calculate Energy Consumed (joules) by estimating it crudely.I have no idea what you're referring to. The power draw is reported right there, and the energy isn't estimated, it's measured precisely. The A55 data is correct.
Perf/W is directly inversely relative to energy consumption if you would actually plot your data.
Kangal - Saturday, November 6, 2021 - link
The Specific Power Draw makes sense in the context of these comparisons. For the longest time in this industry, they've always talked about Performance per Watt. No-one, not even Intel (and they've been know to be quite shady) uses Performance per Joules.The total energy consumed in Joules is simply irrational. One can then make a flawed comparison of how much processing could be made through the consumption of a cupcake if you read it's nutritional content. Not only that, if you actually look at the data you guys submitted, it has a lot more variance with Joules, whilst Watts shows a lot more consistent results. Your energy consumed is an estimate, not what is specifically used by the cores when running.
For instance, when using Joules, it makes Apple's Efficiency cores seem to use slightly less power than a Cortex-A55, whilst performing benchmarks slightly faster than a Cortex-A76. If that is true, then no Android phones would be sold above $500 as everyone would simply buy iPhones. It's like comparing a 2011 processor (48nm Dual Cortex-A9) to a 2015 processor (16nm Octa Cortex-A53), so it's not only using less power, but delivering more than x4 times the performance. Ludicrous. You just cannot magically wave away discrepancies that big (x7.43). On the other hand, if you plot it using Watts, you get a deeper picture. Apple's Efficiency cores use about double the energy as a Cortex-A55 but in turn they deliver four times the performance, so the net difference is a much more palatable x2.14 leap in efficiency (at least in max performance comparison). And I'm comparing the latest Apple (A15) to Android (QSD 888) cores.
If the A55 data is as accurate as you say, why do you have discrepancies there as well?
For example, QSD 888 versus Google Silicon-101... they're both using off-the-shelf Cortex-A55. Yet, the Qualcomm's chipset is apparently drawing only 0.30 Watts, compared to 0.59 Watts... which is about x2 less. And both perform fairly close scores at 0.85 versus 0.88, making their total efficiency difference of x1.90 (2.83 vs 1.49) puzzling. So something is a miss. Going off the Joules Estimates doesn't fix the issue either, as you still have an unaccounted x1.83 difference in efficiency still.
With all your resources, you guys never got curious about such discrepancies?
(sorry for being a little obtuse)
dotjaz - Sunday, November 7, 2021 - link
You are obviously uneducated, and don't know what "off-the-shelf" means in any chips. Physical implementation varies a lot even on the same process with the same IP. Either you or Cadence are lying. I'd rather believe a reputable company with decades of experience.https://www.anandtech.com/show/16836/cadence-cereb...
Kangal - Sunday, November 7, 2021 - link
Snapdragon 888: 4x Cortex-A55 @ 1.80GHz 4x128KB pL2, with 4MB sL3, on Samsung5nm (5LPE)
Google Tensor: 4x Cortex-A55 @ 1.80GHz 4x128KB pL2, with 4MB sL3, on Samsung
5nm (5LPE)
Both of these SoC's are using Cortex-A55 cores which were licensed from ARM directly. They are off-the-shelf. These are not custom cores, such as the Mongoose, Early-Kyro, Krait, Denver, Carmel, or the 8-or-so different custom designs released by Apple. If you say that I am lying, then you are also saying that both Google, Qualcomm, are also lying. And note, that they are virtually identical in their specifications and build.
I think you entirely mis-understood the point of Cadence is about. Sure, even on the same chips there are variance, the so-called "silicon lottery". But be realistic, how much of a difference do you think it is? I'll give a hint, the larger the silicon, the more the variance, and the bigger the difference. If you check the latest data from the now bankrupt siliconlottery.com service, the difference with the 3950X is (worst) 4.00Ghz versus 4.15Ghz (best). At best that is a 3-point-something-percent difference, so let's say it is 5%... and this difference is likely to be less on smaller chips. But even if we accept 5%, that is nowhere near x2 variance.
Also, you would be calling AnandTech liars as well:
" the new Cortex-A77 picks up where the Cortex-A76 left off and follows Arm’s projected trajectory of delivering a continued SOLID PERFORMANCE UPLIFT of 20-25% CAGR "...
How is it that we are able to be impressed by a +20% uplift, yet, we completely disregard a +90% difference? It is not logical, and doesn't pass the sniff test. You can call me uneducated all you like, I'm trying to arrive at the truth, since there are big discrepancies with the data provided that I've pointed out to above. I am open to criticism, as everyone should be.
TellowKrinkle - Tuesday, November 9, 2021 - link
Let's look at some unitsPerformance is units of calculation work divided by time. For our graph, some constant times spec runs per second.
Performance per watt is then some constant times (spec runs) / (seconds * watts)
The joules measurement put up there is specifically joules per spec run. One joule is one watt second, so that number would therefore be (watts * seconds) / (spec runs).
Notice the similarity? Joules is 1/(perf per watt).
Hopefully it's clear from this that the "joules" measurement on that graph *is* there to indicate efficiency, just like a perf/watt measurement would be. The only difference is that in the joules graph, high numbers indicate inefficient processors, while in a perf/watt graph, those would be represented by low numbers.
The0ne - Thursday, November 4, 2021 - link
Pixel 4A updated last night to 12 and it runs even smoother. The UI tricks they have done does appear to make a visual difference. So far I'm impressed with 12 aside from the gigantic texts and bars here and there.