AMD Radeon R9 285 Review: Feat. Sapphire R9 285 Dual-X OC
by Ryan Smith on September 10, 2014 2:00 PM ESTTonga’s Microarchitecture - What We’re Calling GCN 1.2
As we alluded to in our introduction, Tonga brings with it the next revision of AMD’s GCN architecture. This is the second such revision to the architecture, the last revision (GCN 1.1) being rolled out in March of 2013 with the launch of the Bonaire based Radeon HD 7790. In the case of Bonaire AMD chose to kept the details of GCN 1.1 close to them, only finally going in-depth for the launch of the high-end Hawaii GPU later in the year. The launch of GCN 1.2 on the other hand is going to see AMD meeting enthusiasts half-way: we aren’t getting Hawaii level details on the architectural changes, but we are getting an itemized list of the new features (or at least features AMD is willing to talk about) along with a short description of what each feature does. Consequently Tonga may be a lateral product from a performance standpoint, but it is going to be very important to AMD’s future.
But before we begin, we do want to quickly remind everyone that the GCN 1.2 name, like GCN 1.1 before it, is unofficial. AMD does not publicly name these microarchitectures outside of development, preferring to instead treat the entire Radeon 200 series as relatively homogenous and calling out feature differences where it makes sense. In lieu of an official name and based on the iterative nature of these enhancements, we’re going to use GCN 1.2 to summarize the feature set.
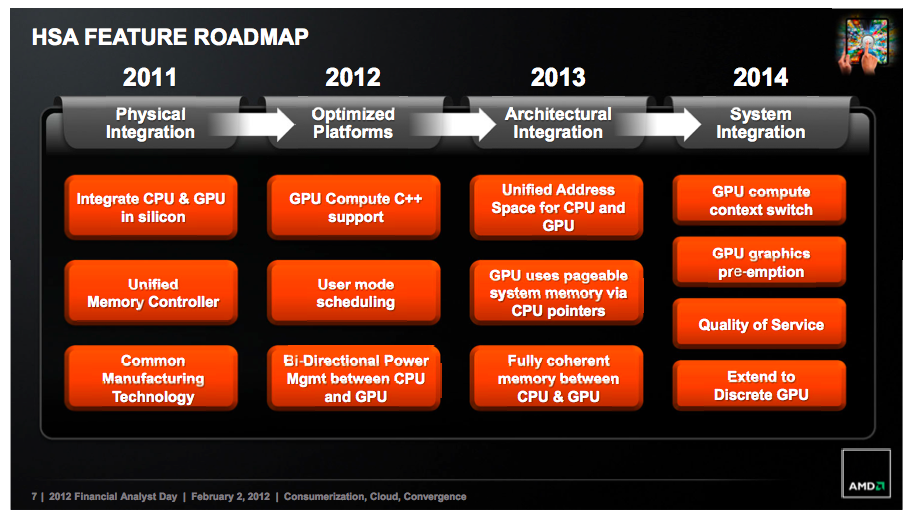
AMD's 2012 APU Feature Roadmap. AKA: A Brief Guide To GCN
To kick things off we’ll pull old this old chestnut one last time: AMD’s HSA feature roadmap from their 2012 financial analysts’ day. Given HSA’s tight dependence on GPUs, this roadmap has offered a useful high level overview of some of the features each successive generation of AMD GPU architectures will bring with it, and with the launch of the GCN 1.2 architecture we have finally reached what we believe is the last step in AMD’s roadmap: System Integration.

It’s no surprise then that one of the first things we find on AMD’s list of features for the GCN 1.2 instruction set is “improved compute task scheduling”. One of AMD’s major goals for their post-Kavari APU was to improve the performance of HSA by various forms of overhead reduction, including faster context switching (something GPUs have always been poor at) and even GPU pre-emption. All of this would fit under the umbrella of “improved compute task scheduling” in AMD’s roadmap, though to be clear with AMD meeting us half-way on the architecture side means that they aren’t getting this detailed this soon.
Meanwhile GCN 1.2’s other instruction set improvements are quite interesting. The description of 16-bit FP and Integer operations is actually very descriptive, and includes a very important keyword: low power. Briefly, PC GPUs have been centered around 32-bit mathematical operations for some number of years now since desktop technology and transistor density eliminated the need for 16-bit/24-bit partial precision operations. All things considered, 32-bit operations are preferred from a quality standpoint as they are accurate enough for many compute tasks and virtually all graphics tasks, which is why PC GPUs were limited to (or at least optimized for) partial precision operations for only a relatively short period of time.
However 16-bit operations are still alive and well on the SoC (mobile) side. SoC GPUs are in many ways a 5-10 year old echo of PC GPUs in features and performance, while in other ways they’re outright unique. In the case of SoC GPUs there are extreme sensitivities to power consumption in a way that PCs have never been so sensitive, so while SoC GPUs can use 32-bit operations, they will in some circumstances favor 16-bit operations for power efficiency purposes. Despite the accuracy limitations of a lower precision, if a developer knows they don’t need the greater accuracy then falling back to 16-bit means saving power and depending on the architecture also improving performance if multiple 16-bit operations can be scheduled alongside each other.
Imagination's PowerVR Series 6XT: An Example of An SoC GPU With FP16 Hardware
To that end, the fact that AMD is taking the time to focus on 16-bit operations within the GCN instruction set is an interesting one, but not an unexpected one. If AMD were to develop SoC-class processors and wanted to use their own GPUs, then natively supporting 16-bit operations would be a logical addition to the instruction set for such a product. The power savings would be helpful for getting GCN into the even smaller form factor, and with so many other GPUs supporting special 16-bit execution modes it would help to make GCN competitive with those other products.
Finally, data parallel instructions are the feature we have the least knowledge about. SIMDs can already be described as data parallel – it’s 1 instruction operating on multiple data elements in parallel – but obviously AMD intends to go past that. Our best guess would be that AMD has a manner and need to have 2 SIMD lanes operate on the same piece of data. Though why they would want to do this and what the benefits may be are not clear at this time.








86 Comments
View All Comments
Samus - Wednesday, September 10, 2014 - link
Am I missing something or is this card slower than the 280...what the hell is going on?tuxRoller - Wednesday, September 10, 2014 - link
Yeah, you're missing something:)Samus - Thursday, September 11, 2014 - link
BF4 its about 4% slower.Kenshiro70 - Wednesday, September 10, 2014 - link
"something of a lateral move for AMD, which is something we very rarely see in this industry"Really? Seems like the industry has been rebadging for the last two release cycles. How about starting to test and show results on 4k screens? 60Hz ones are only $500 now, and that will put a little pressure on the industry to stop coasting. I have no intention of spending money on a minor bump up in specs. Bitcoin mining demand can't last forever.
tuxRoller - Wednesday, September 10, 2014 - link
Error page 4: chart should read "lower is better"jeffrey - Wednesday, September 10, 2014 - link
Saw this too, the Video Encode chart Ryan.Congrats btw!
Ryan Smith - Thursday, September 11, 2014 - link
Whoops. Thanks.yannigr2 - Wednesday, September 10, 2014 - link
Great article and review.The only bad news here I think is Mantle.
But on this matter, about Mantle, maybe a slower processor could show less of that performance drop or even keep performing better than DirectX11. Maybe one more test on a slower core, on an FX machine?
mapesdhs - Wednesday, September 10, 2014 - link
What were AMD thinking? How can the 285 be a replacement for the 280, given itsreduced VRAM, while at the same time AMD is pushing Mantle? Makes no sense at all.
Despite driver issues, I'd kinda gotten used to seeing AMD be better than NVIDIA in
recent times for VRAM capacity. A new card with only 2GB is a step backwards. All
NVIDIA has to do is offer a midrange Maxwell with a minimum 4GB and they're home.
No idea if they will. Time will tell.
Ian.
Alexvrb - Wednesday, September 10, 2014 - link
There you have it, and with no issues with boost. Sorry Chizow, so much for that. :PThanks for the in-depth review, Ryan. It appears that power consumption is going to vary from implementation to implementation. Lacking a reference model makes it tricky. Another review I read compared Gigabyte's Windforce OC 285 to a similarly mild OC'd 280, finding a substantial difference in the 285's favor.