Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM ESTGracemont Microarchitecture (E-Core) Examined
The smaller core as part of Intel’s hybrid Alder Lake design is called an E-core, and is built on the Gracemont microarchitecture. It forms part of Intel’s Atom family of processors, and is a significant microarchitectural jump over the previous Atom core design called Tremont.
- 2008: Bonnell
- 2011: Saltwell
- 2013: Silvermont
- 2015: Airmont
- 2016: Goldmont
- 2017: Goldmont Plus
- 2020: Tremont
- 2021: Gracemont

Based on Intel’s diagrams, the company is pitching that the size of its Golden Cove core means that in the space it would normally fit one of its P-core designs, it can enable a four core cluster of E-cores along with a shared 4MB L2 cache between them.
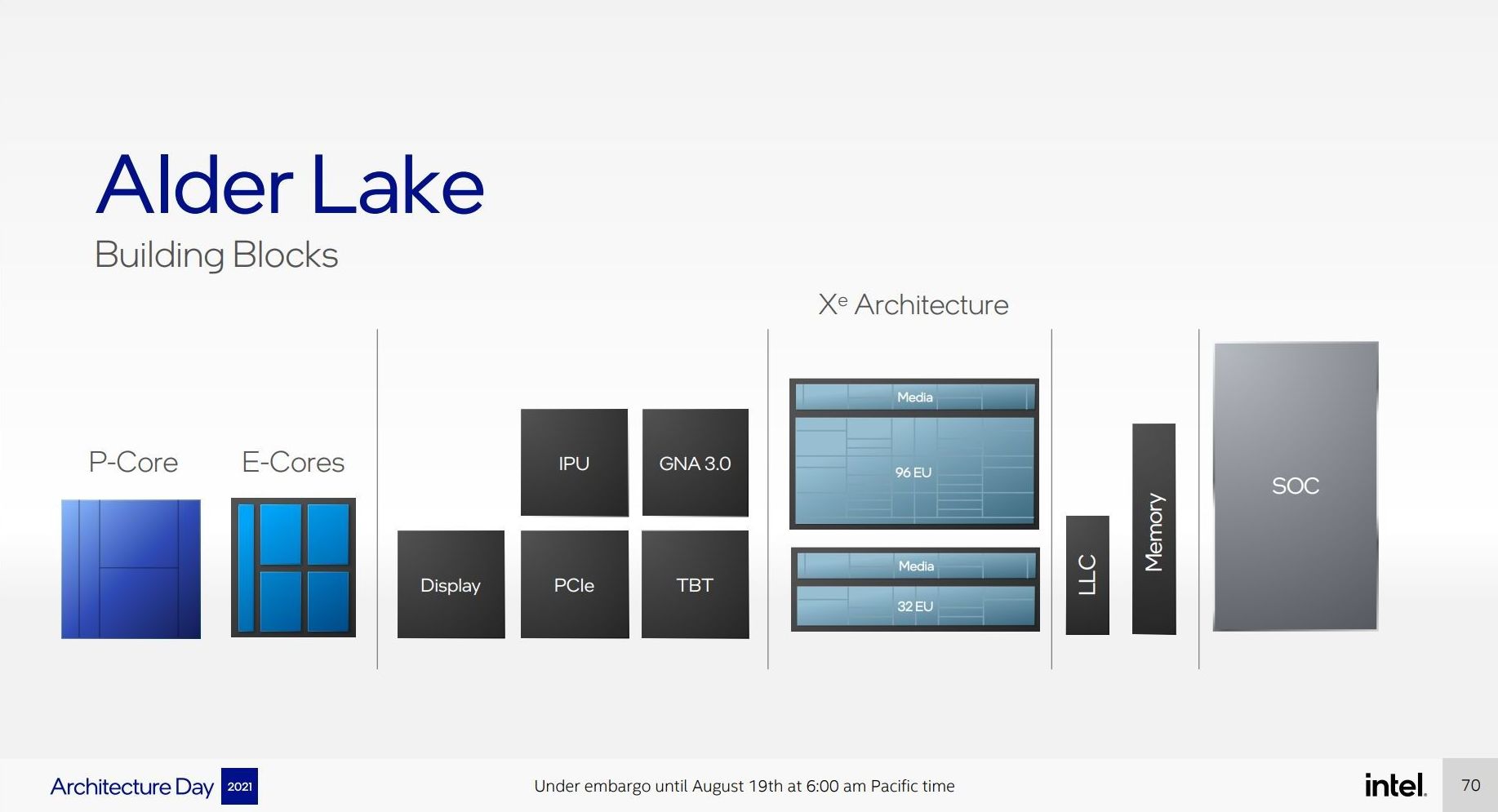
For performance, Intel has some pretty wild claims. It splits them up into single thread and multi-thread comparisons using SPECrate2017_int.
When comparing 1C1T of Gracemont against 1C1T of Skylake, Intel’s numbers suggest:
- +40% performance at iso-power (using a middling frequency)
- 40% less power* at iso-performance (peak Skylake performance)
*'<40%' is now stood to mean 'below 40 power'
When comparing 4C4T of Gracemont against 2C4T of Skylake, Intel’s numbers suggest:
- +80% performance peak vs peak
- 80% less power at iso performance)peak Skylake performance
We pushed the two Intel slides together to show how they presented this data.
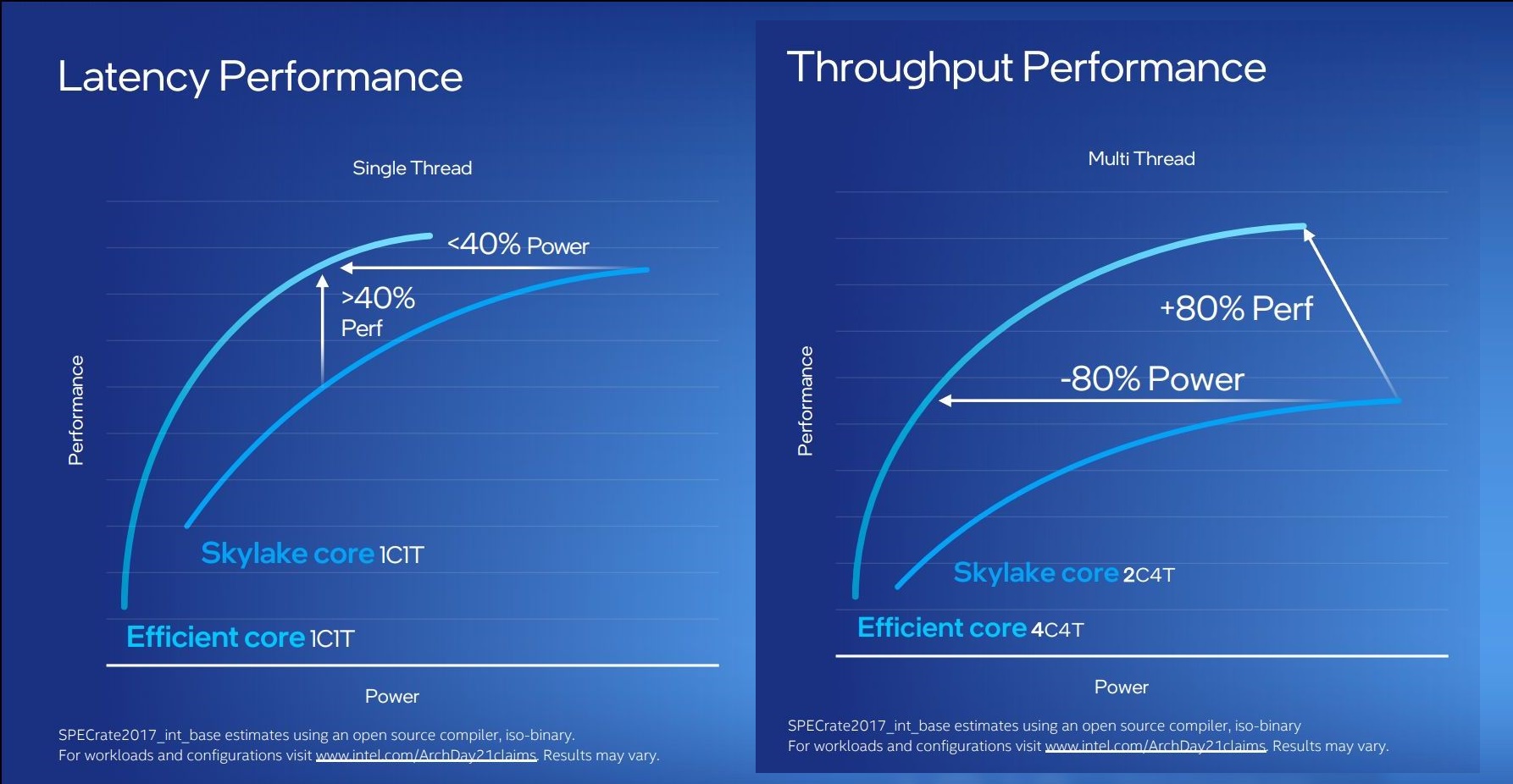
By these graphics it looks like that for peak single thread, we should see around +8% better than Skylake performance while consuming just over half the power – look for Cinebench R20 scores for one Gracemont thread around 478 then (Skylake 6700K scored 443). With +8% for single thread in mind, the +80% in MT comparing 4 cores of Gracemont to two fully loaded Skylake cores seems a little low – we’ve got double the physical cores with Gracemont compared to Skylake here. But there’s likely some additional performance regression with the cache structure on the new Atom core, which we’ll get to later on this page.
These claims are substantial. Intel hasn’t compared the new Atom core generation on generation, because it felt that having AVX2 support would put the new Atom at a significant advantage. But what Intel is saying with these graphs is that we should expect better-than Skylake performance at much less power. We saw Skylake processors up to 28 cores in HEDT – it makes me wonder if Intel might not enable its new Atom core for that market. If that’s the case, where is our 64-core Atom version for HEDT? I’ll take one.
Front End
The big item about the Tremont front end of the core was the move to dual three-wide decode paths, enabling two concurrent streams of decode that could support 3 per cycle. That still remains in Gracemont, but is backed by a double-size 64 KB L1 Instruction cache. This ties into the branch predictor which enables prefetchers at all cache levels, along with a 5000-entry branch target cache which Intel says in improved over the previous generation.

Back on the decoder, Intel supports on-demand decode which stores a history of previous decodes in the instruction cache and if recent misses are recalled at the decode stage, the on-demand stream will pull directly from the instruction cache instead, saving time – if the prefetch/decode works, the content in the instruction cache is updated, however if it is doing poorly then the scope is ‘re-enabled for general fetches’ to get a better understanding of the instruction flow. This almost sounds like a micro-op cache without having a physical cache, but is more to do about instruction streaming. Either way, the decoders can push up to six uops into the second half of the front end.
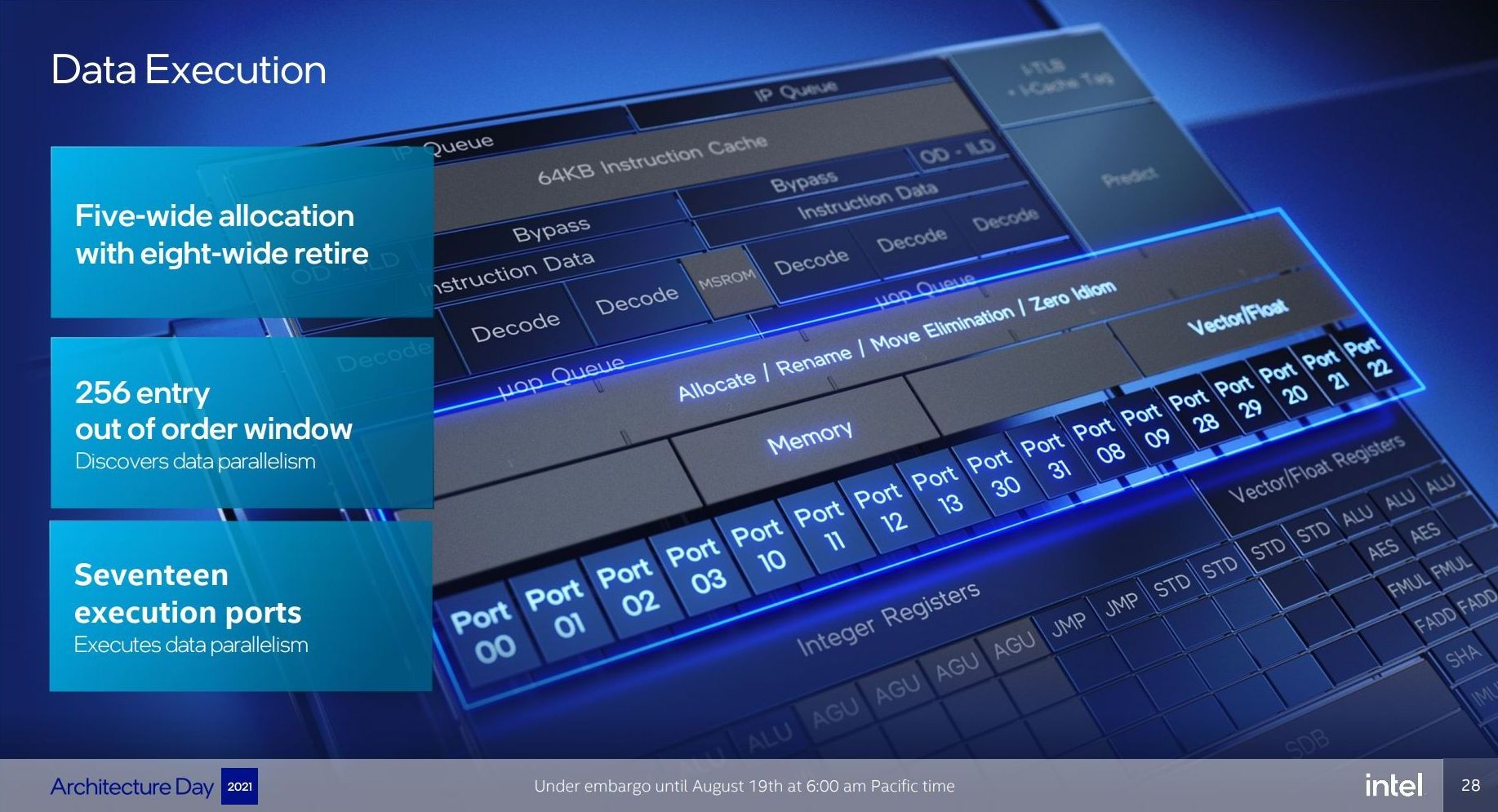
For Gracemont, the reorder buffer size has increased from 208 in Tremont to 256, which is important aspect given that Gracemont now has a total of 17 (!) execution ports, compared to eight in Tremont. This is also significantly wider than the execution capabilities of Golden Cove's 12 ports, related to the disaggregated integer and FP/vector pipeline design. However, despite that width, the allocation stage feeding into the reservation stations can only process five instructions per cycle. On the return path, each core can retire eight instructions per cycle.
Back End
So it’s a bit insane to have 17 execution ports here. There are a lot of repeated units as well, which means that Gracemont is expecting to see repeated instruction use and requires the parallelism to do more per cycle and then perhaps sit idle waiting for the next instructions to come down the pipe. Overall we have
- 4 Integer ALUs (ALU/Shift), two of which can do MUL/DIV
- 4 Address Generator Units, 2 Load + 2 Store
- 2 Branch Ports
- 2 Extra Integer Store ports
- 2 Floating Point/Vector store ports
- 3 Floating Point/Vector ALUs: 3x ALUs, 2x AES/FMUL/FADD, 1x SHA/IMUL/FDIV
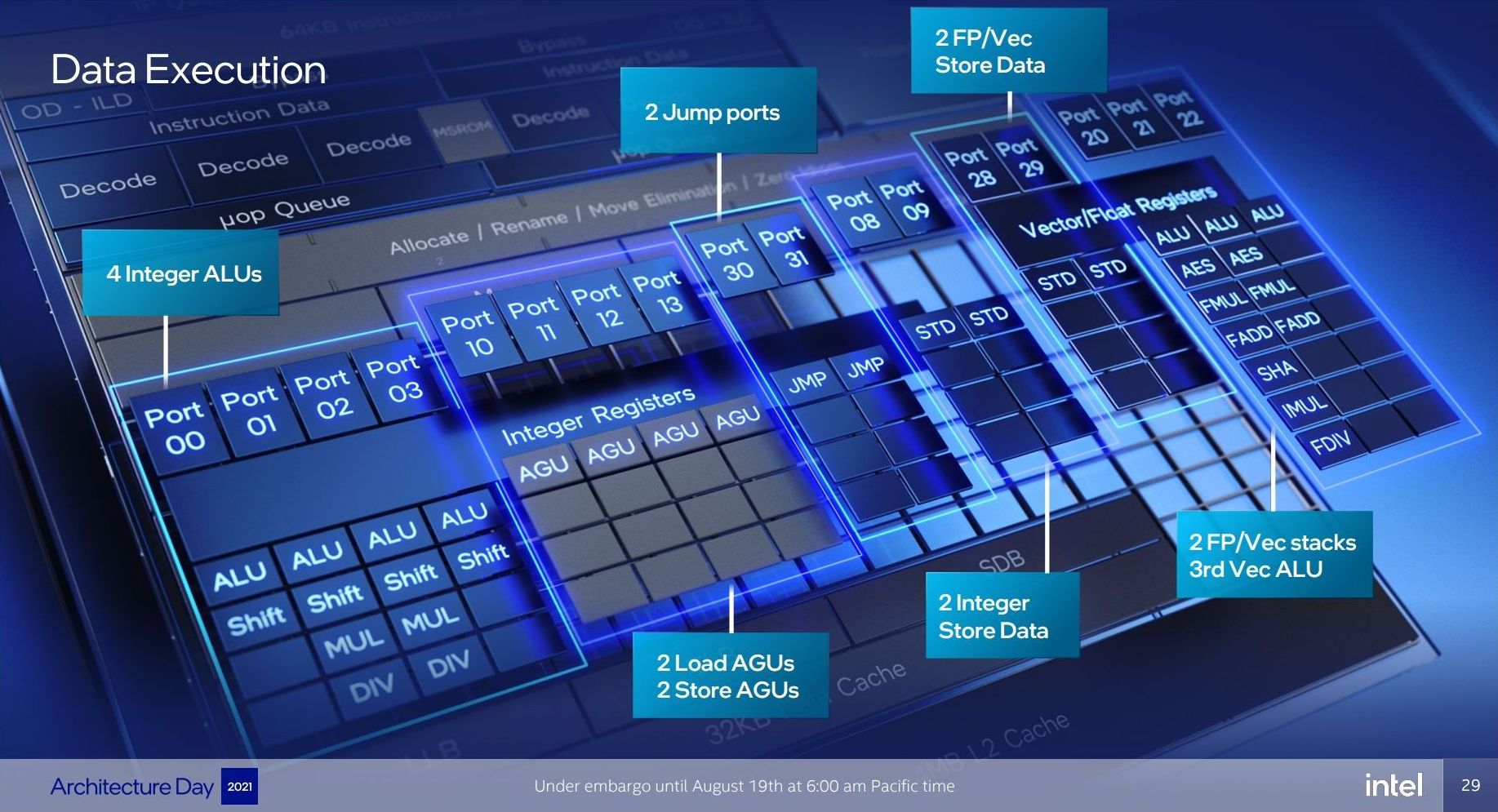
It will be interesting to see exactly how many of these can be accessed simultaneously. In previous core designs a lot of this functionality would be enabled though the same port – even Alder Lake’s P-core only has 12 execution ports, with some ports doing double duty on Vector and Integer workloads. In the P-core there is a single scheduler for both types of workloads, whereas in the E-core there are two separate schedulers, which is more akin to what we see on non-x86 core designs. It’s a tradeoff in complexity and ease-of-use.

The back-end is support by a 32 KiB L1-Data cache, which supports a 3-cycle pointer chasing latency and 64 outstanding cache misses. There are two load and two store ports, which means 2x16 byte loads and 2 x 16 byte stores to the L1-D.
There is also has a shared 4 MB L2 cache across all four E-cores in a cluster with 17-cycle latency. The shared L2 cache can support 64 bytes per cycle read/write per core, which Intel states is sufficient for all four cores. The new L2 supports up to 64 outstanding misses to the deeper memory subsystem – which seems fair, but has to be shared amongst the 4 cores.
Intel states that it has a Resource Director that will arbitrate cache accesses between the four cores in a cluster to ensure fairness, confirming that Intel are building these E-cores in for multi-threaded performance rather than latency sensitive scenarios where one thread might have priority.
Other Highlights
As the first Atom core to have AVX2 enabled, there are two vector ports that support FMUL and FADD (port 20 and port 21), which means that we should expect peak performance compared to previous Atoms to be substantial. The addition of VNNI-INT8 over the AVX unit means that Intel wants these E-cores to enable situations where high inference throughput is needed, such as perhaps video analysis.
Intel was keen to point out that Gracemont has all of its latest security features including Control Flow Enhancement Technology (CET), and virtualization redirects under its VT-rp feature.
Overall, Intel stated that the E-cores are tuned for voltage more than anything else (such as performance, area). This means that the E-cores are set to use a lot less power, which may help in mobile scenarios. But as mentioned before on the first page, it will depend on how much power the ring has to consume in that environment - it should be worth noting that each four core Atom cluster only has a single stop on the full ring in Alder Lake, which Intel says should not cause congestion but it is a possibility – if each core is fully loaded, there is only 512 KB of L2 cache per core before making the jump to main memory, which indicates that in a fully loaded scenario, that might be a bottleneck.








223 Comments
View All Comments
mode_13h - Thursday, August 19, 2021 - link
Indeed. But, remember that it's a Skylake from 2015, fabbed on Intel's original 14 nm node, and it's an integer workload they measured. If they measured vector or FPU workloads, the results would probably be rather different.Spunjji - Monday, August 23, 2021 - link
Indeed. Based on how Intel usually do their marketing, I'm not expecting anything revolutionary from those cores. Maybe I'll be surprised, but I'm expecting mild disappointment.mode_13h - Tuesday, August 24, 2021 - link
Having already bought into the "Atom" series at Apollo Lake, for a little always-on media streaming server, I'm already thrilled! Tremont was already a bigger step up than I expected.Spunjji - Tuesday, August 24, 2021 - link
Fair - I've just been a bit burned! Last time I used an Atom device was Bay Trail, and at the time there was a big noise about its performance being much better than previous Atom processors. The actual experience was not persuasive!Silver5urfer - Thursday, August 19, 2021 - link
Too many changes in the CPU x86 topology. They are making this CPU a heavily dependent one of the OS side with such insane changes to the Scheduler system, like P, E and then the Hyperthreading of P cores. On top of all this the DRAM system must be good else all that 19% big IPC boost will be wasted just like on Rocket Lake. Finally Windows 11 only ? dafaq.I have my doubts on this Intel IDT and the whole ST performance along with gaming SMT/HT performance. Until the CPU is out it's hard to predict the things. Also funny they are simply adding the older Skylake cores to the processor in a small format without HT, while claiming this ultra hybrid nonsense, seems like mostly tuned for a mobile processor than a Desktop system which is why there's no trash cores on the HEDT Sapphire Rapids Xeon. And which Enterprise wants to shift to this new nonsense of x86 landscape. On top we have Zen 4 peaking at 96Core 192T hyperbeast Genoa which also packs AVX512.
I'm waiting Intel, also AMD for their 3D V Cache Zen 3 refresh. Plus whoever owns any latest processors from Intel or AMD should avoid this Hardware like plague, it's too much of a beta product and OS requirements, DRAM pricing problems will be there for Mobos and RAM kits and PCIe5.0 is just damn new and has no usage at all right now It all feels just like Zen when AMD came with NUMA system and refined it well by the Zen 3. I doubt AMD will have any issue with this design. But one small good news is some competition ?
Silver5urfer - Thursday, August 19, 2021 - link
Also scalable lol. This design is peaked out at 8C16T and 8 small cores while Sapphire Rapids is at 56Cores 112T. AMD's Zen 4 ? 96C/192T lmao that battle is going to be good. Intel is really done with x86 is what I get from this, copying everything from AMD and ARM. Memory Interconnects, Big Little nonsense. Just release the CPU and let it rip Intel, we want to see how it works against 10900Ks and 5900Xs.mode_13h - Friday, August 20, 2021 - link
> Also funny they are simply adding the older Skylake cores> to the processor in a small format without HT
They're not Skylake cores, of course. They're smaller & more power-efficient, but also a different uArch. 3+3-wide decode, instead of 4-wide, and no proper uop cache. Plus, the whole thing about 17 dispatch ports.
If you back-ported these to 14 nm, they would lose their advantages over Skylake. If they forward-ported Skylake to "Intel 7", it would probably still be bigger and more power-hungry. So, these are different, for good reasons.
vyor - Friday, August 20, 2021 - link
I believe they have a uOP cache though?mode_13h - Saturday, August 21, 2021 - link
No, Tremont and Gracemont don't have a uop cache. And if Goldmont didn't, then it's probably safe to say that none of the "Atom" cores did.The article does mention that some aspects of the instruction cache make it sound a bit like a uop cache.
Silver5urfer - Saturday, August 21, 2021 - link
I see the only reason - Intel was forced to shrink the SKL and shove them in this designs because their node Fabs are busted. Their Rocket Lake is a giant power hog. Insane power draw. Intel really shined until 10900K, super fast cores, ultra strong IMC that can handle even 5000MHz and any DRAM. Solid SMT. High power but it's a worth trade off.With RKL, backport Intel lost - IMC leadership, SMT performance, ST performance (due to Memory latency) AND efficiency PLUS Overclockability. That was the time I saw Intel's armor cracking. HEDT was dead so was Xeon but the only reason Mainstream LGA1200 stood was super strong ring bus even on RKL.
Now FF to 10SF or Intel 7 whatever they call it. No more high speed IMC now even double whammy due to the dual ring system and the ring is shared by all the cores connected, I doubt these SKL cores can manage the highspeed over 3800MHz DDR4 RAM, which is why they are mentioning Dynamic Clocking for Memory, this will have Gearing memory system for sure. High amount of efficiency focus due to the Laptop market from Apple and AMD pressure. No more big core SMT/HT performance. Copying ARMs technology onto x86 is pathetic. ARM processors never did SMT x86 had this advantage. But Intel is losing it because their 10nm is a dud. Look at the leaked PL1,2,4 numbers. It doesn't change at all, they crammed 8 phone cores and still it's higher and higher.
Look at HEDT, Sapphire Rapids, tile approach, literally copied everything they could from AMD and tacked on HBM for HPC money. And I bet the power consumption would be insanely high due to no more phone cores cheating only big x86 real cores. Still they are coming back. At this point Intel would have released "Highest Gaming Performance" marketing for ADL, so far none and release is just 2 months. RKL had that campaign before 2 months and CFL, CML all of them had. This one doesn't and they are betting on I/O this time.
Intel has to show the performance. And it's not like AMD doesn't know this, which is why Lisa Su showed off a strong 15% gaming boost. And remember when AMD showcases the CPUs ? Direct benchmarks against Intel's top - 9900K, 10900Ks all over the place. No sign of 5900X or 5950X comparisons from Intel.