Intel Architecture Day 2021: Alder Lake, Golden Cove, and Gracemont Detailed
by Dr. Ian Cutress & Andrei Frumusanu on August 19, 2021 9:00 AM ESTGracemont Microarchitecture (E-Core) Examined
The smaller core as part of Intel’s hybrid Alder Lake design is called an E-core, and is built on the Gracemont microarchitecture. It forms part of Intel’s Atom family of processors, and is a significant microarchitectural jump over the previous Atom core design called Tremont.
- 2008: Bonnell
- 2011: Saltwell
- 2013: Silvermont
- 2015: Airmont
- 2016: Goldmont
- 2017: Goldmont Plus
- 2020: Tremont
- 2021: Gracemont

Based on Intel’s diagrams, the company is pitching that the size of its Golden Cove core means that in the space it would normally fit one of its P-core designs, it can enable a four core cluster of E-cores along with a shared 4MB L2 cache between them.
For performance, Intel has some pretty wild claims. It splits them up into single thread and multi-thread comparisons using SPECrate2017_int.
When comparing 1C1T of Gracemont against 1C1T of Skylake, Intel’s numbers suggest:
- +40% performance at iso-power (using a middling frequency)
- 40% less power* at iso-performance (peak Skylake performance)
*'<40%' is now stood to mean 'below 40 power'
When comparing 4C4T of Gracemont against 2C4T of Skylake, Intel’s numbers suggest:
- +80% performance peak vs peak
- 80% less power at iso performance)peak Skylake performance
We pushed the two Intel slides together to show how they presented this data.
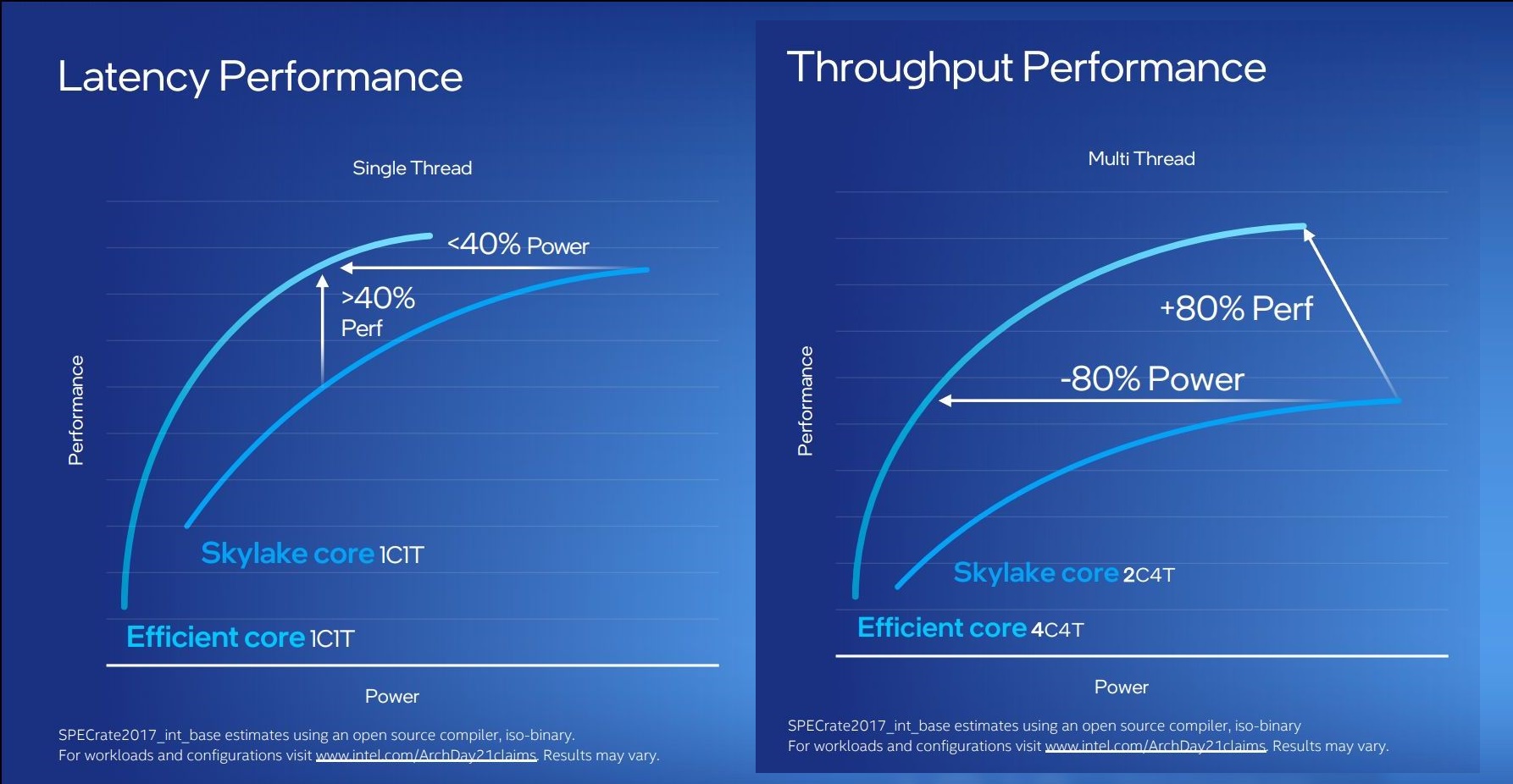
By these graphics it looks like that for peak single thread, we should see around +8% better than Skylake performance while consuming just over half the power – look for Cinebench R20 scores for one Gracemont thread around 478 then (Skylake 6700K scored 443). With +8% for single thread in mind, the +80% in MT comparing 4 cores of Gracemont to two fully loaded Skylake cores seems a little low – we’ve got double the physical cores with Gracemont compared to Skylake here. But there’s likely some additional performance regression with the cache structure on the new Atom core, which we’ll get to later on this page.
These claims are substantial. Intel hasn’t compared the new Atom core generation on generation, because it felt that having AVX2 support would put the new Atom at a significant advantage. But what Intel is saying with these graphs is that we should expect better-than Skylake performance at much less power. We saw Skylake processors up to 28 cores in HEDT – it makes me wonder if Intel might not enable its new Atom core for that market. If that’s the case, where is our 64-core Atom version for HEDT? I’ll take one.
Front End
The big item about the Tremont front end of the core was the move to dual three-wide decode paths, enabling two concurrent streams of decode that could support 3 per cycle. That still remains in Gracemont, but is backed by a double-size 64 KB L1 Instruction cache. This ties into the branch predictor which enables prefetchers at all cache levels, along with a 5000-entry branch target cache which Intel says in improved over the previous generation.

Back on the decoder, Intel supports on-demand decode which stores a history of previous decodes in the instruction cache and if recent misses are recalled at the decode stage, the on-demand stream will pull directly from the instruction cache instead, saving time – if the prefetch/decode works, the content in the instruction cache is updated, however if it is doing poorly then the scope is ‘re-enabled for general fetches’ to get a better understanding of the instruction flow. This almost sounds like a micro-op cache without having a physical cache, but is more to do about instruction streaming. Either way, the decoders can push up to six uops into the second half of the front end.
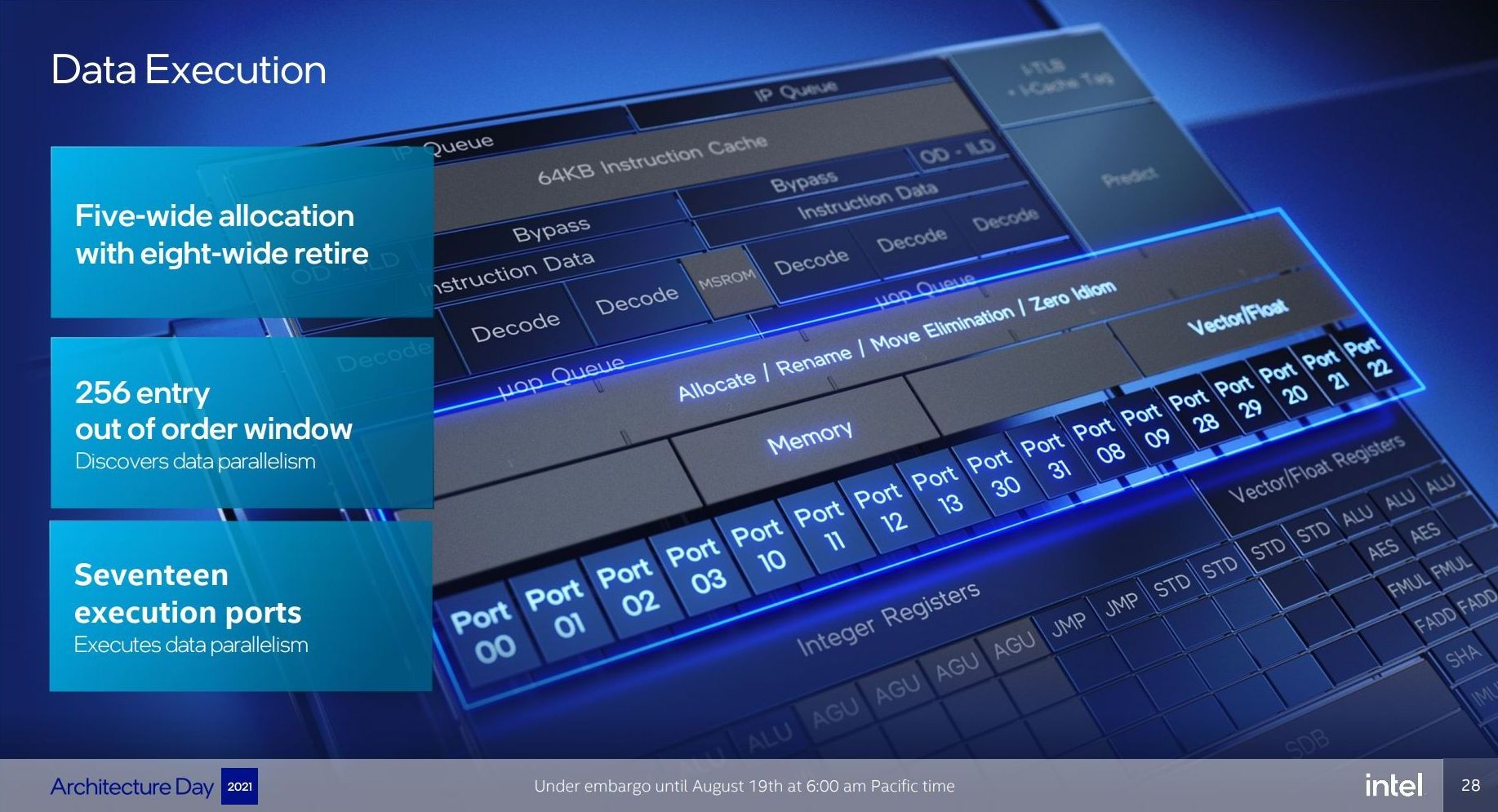
For Gracemont, the reorder buffer size has increased from 208 in Tremont to 256, which is important aspect given that Gracemont now has a total of 17 (!) execution ports, compared to eight in Tremont. This is also significantly wider than the execution capabilities of Golden Cove's 12 ports, related to the disaggregated integer and FP/vector pipeline design. However, despite that width, the allocation stage feeding into the reservation stations can only process five instructions per cycle. On the return path, each core can retire eight instructions per cycle.
Back End
So it’s a bit insane to have 17 execution ports here. There are a lot of repeated units as well, which means that Gracemont is expecting to see repeated instruction use and requires the parallelism to do more per cycle and then perhaps sit idle waiting for the next instructions to come down the pipe. Overall we have
- 4 Integer ALUs (ALU/Shift), two of which can do MUL/DIV
- 4 Address Generator Units, 2 Load + 2 Store
- 2 Branch Ports
- 2 Extra Integer Store ports
- 2 Floating Point/Vector store ports
- 3 Floating Point/Vector ALUs: 3x ALUs, 2x AES/FMUL/FADD, 1x SHA/IMUL/FDIV
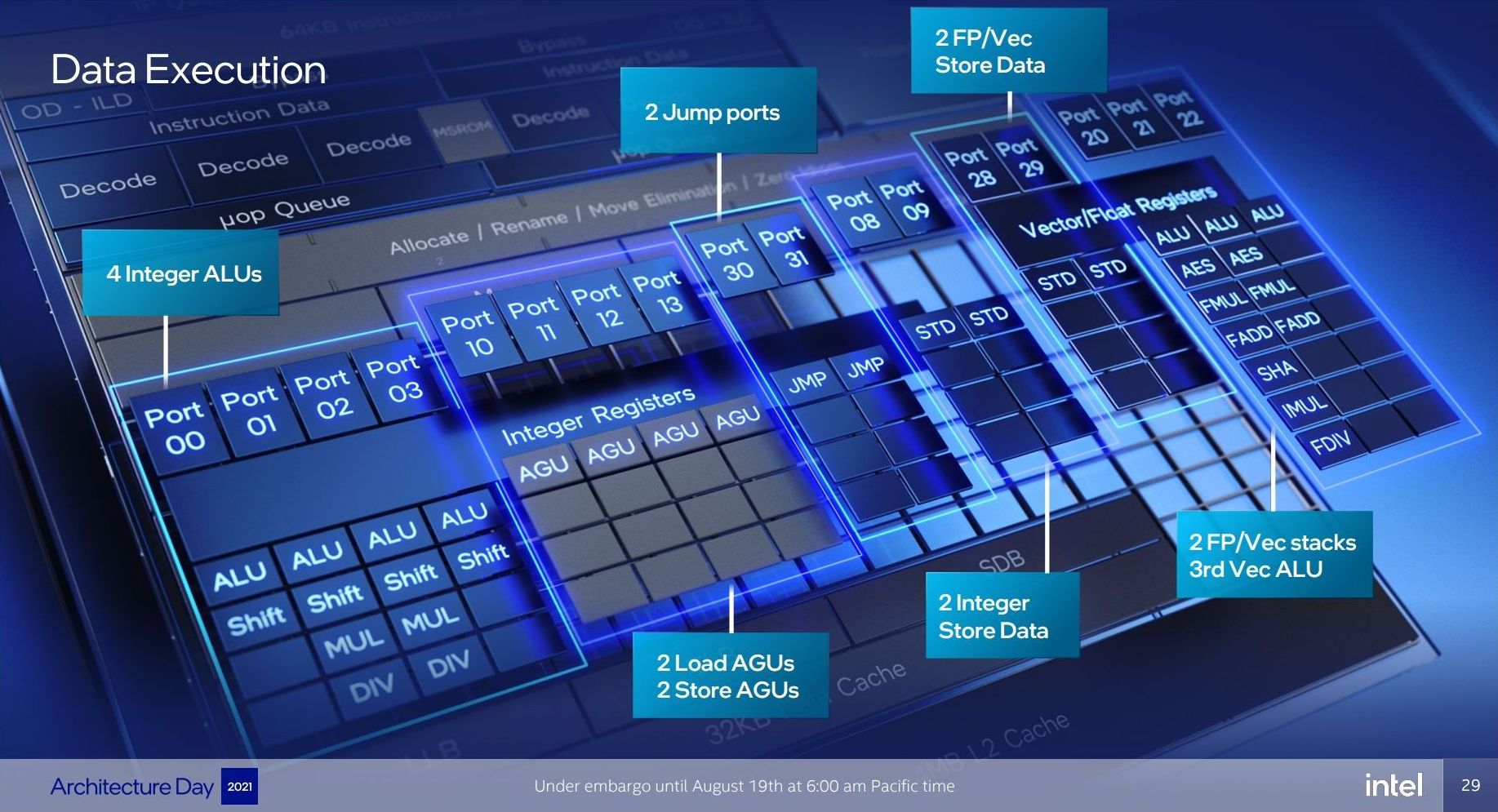
It will be interesting to see exactly how many of these can be accessed simultaneously. In previous core designs a lot of this functionality would be enabled though the same port – even Alder Lake’s P-core only has 12 execution ports, with some ports doing double duty on Vector and Integer workloads. In the P-core there is a single scheduler for both types of workloads, whereas in the E-core there are two separate schedulers, which is more akin to what we see on non-x86 core designs. It’s a tradeoff in complexity and ease-of-use.

The back-end is support by a 32 KiB L1-Data cache, which supports a 3-cycle pointer chasing latency and 64 outstanding cache misses. There are two load and two store ports, which means 2x16 byte loads and 2 x 16 byte stores to the L1-D.
There is also has a shared 4 MB L2 cache across all four E-cores in a cluster with 17-cycle latency. The shared L2 cache can support 64 bytes per cycle read/write per core, which Intel states is sufficient for all four cores. The new L2 supports up to 64 outstanding misses to the deeper memory subsystem – which seems fair, but has to be shared amongst the 4 cores.
Intel states that it has a Resource Director that will arbitrate cache accesses between the four cores in a cluster to ensure fairness, confirming that Intel are building these E-cores in for multi-threaded performance rather than latency sensitive scenarios where one thread might have priority.
Other Highlights
As the first Atom core to have AVX2 enabled, there are two vector ports that support FMUL and FADD (port 20 and port 21), which means that we should expect peak performance compared to previous Atoms to be substantial. The addition of VNNI-INT8 over the AVX unit means that Intel wants these E-cores to enable situations where high inference throughput is needed, such as perhaps video analysis.
Intel was keen to point out that Gracemont has all of its latest security features including Control Flow Enhancement Technology (CET), and virtualization redirects under its VT-rp feature.
Overall, Intel stated that the E-cores are tuned for voltage more than anything else (such as performance, area). This means that the E-cores are set to use a lot less power, which may help in mobile scenarios. But as mentioned before on the first page, it will depend on how much power the ring has to consume in that environment - it should be worth noting that each four core Atom cluster only has a single stop on the full ring in Alder Lake, which Intel says should not cause congestion but it is a possibility – if each core is fully loaded, there is only 512 KB of L2 cache per core before making the jump to main memory, which indicates that in a fully loaded scenario, that might be a bottleneck.








223 Comments
View All Comments
TristanSDX - Thursday, August 19, 2021 - link
"decreasing the manufacturing cost for Alder Lake, by using all the defect chips and reserving the good ones for Sapphire Rapids."Alder Lake and Shapire Rapids are two totally diffrerent chips
mode_13h - Thursday, August 19, 2021 - link
> Designed as its third generation of vector instructionsDepends on how you're counting. First is definitely MMX. That was extended in a few subsequent CPUs, but they didn't call those extensions MMX2 or anything. MMX was strictly integer, however, and total vector width was 64 bits. MMX had the annoying feature of reusing the FPU registers, which complicated mixing it with x87 code and basically requiring a state reset, when going from MMX -> x87 code.
Then, SSE came along and added single-precision floating-point. It also added a distinct set of vector registers, which were 128 bits. Finally, it included scalar single-precision arithmetic operations, beginning the era of x87's obsolescence.
SSE2 followed with double-precision and integer operations, making MMX obsolete and further replacing x87 functionality.
SSE3, the wondefully-named SSSE3, and a couple rounds of SSE4 came along, but all were basically just rounds of various additions to flesh out what SSE/SSE2 introduced.
Then, AVX was introduced as something of a replacement for SSE. AVX registers are 256 bits. Like SSE, AVX was initially just including single-precision floating-point support. And like SSE2, AVX2 added double-precision and integer operations.
Then, Xeon Phi (2nd gen) and Skylake-SP introduced the first variations on AVX-512 support. You can see what a mess AVX-512 is, here:
https://en.wikipedia.org/wiki/AVX-512#CPUs_with_AV...
Anyway, AVX-512 should be considered Intel's FOURTH family of vector computing instructions, in x86. I think the first time they dabbled with vector instructions was in the venerable i860 - a very cool, but also fairly problematic step in the history of computing.
> (AVX is 128-bit, AVX2 is 256-bit, AVX512 is 512-bit),
No, not at all. The register width for AVX and AVX2 is 256 bits, as I explained above.
However, even that is a slight simplification. AVX introduced some refinements in vector programming, such as a more compiler-friendly 3-operand format. Therefore, it was meant to subsume SSE usage, and included support for 128-bit operations. Similarly, AVX-512 introduced further refinements and the capability to use it on 128-bit and 256-bit operands.
For more, see: https://en.wikipedia.org/wiki/AVX-512#Encoding_and...
mode_13h - Thursday, August 19, 2021 - link
One more correction:> Some workloads can be vectorised – multiple bits of consecutive data all require
> the same operation, so you can pack them into a single register and perform it
> all at once with a single instruction.
Intel's vector instruction extensions aren't strictly SIMD. They include horizontal operations that you don't see in classical SIMD processors or most GPUs.
mode_13h - Thursday, August 19, 2021 - link
> One could argue that if the AVX-512 unit was removed from the desktop> cores that they would be a lot smaller
That's what I thought, but the area overhead it added to a Skylake-SP core was estimated at a mere 11%.
https://www.realworldtech.com/forum/?threadid=1932...
Of course, we can't yet know how much of Golden Cove it occupies, but still probably somewhere in that ballpark.
mode_13h - Thursday, August 19, 2021 - link
> Intel isn’t even supporting AVX-512 with a dual-issuePerhaps because AVX-512 doubled the number and size of vector registers. So, just the vector register file alone would grow 4x in size.
Schmide - Thursday, August 19, 2021 - link
64bit packed doubles are in avx as are some 64bit ints. AVX2 filled in a lot of gaps such as full vector operands and reorders. So as much as AVX2 finished off the 32 and 64bit ints (epi) functions. There was already a fair amount in avx.Schmide - Thursday, August 19, 2021 - link
not to be misleading. There were really no usable int functions in avx other than load and store.maroon1 - Thursday, August 19, 2021 - link
Gracemont beats skylake ???? Really ? I'm reading the article correctlySo these small cores are actually very powerful !!
vegemeister - Thursday, August 19, 2021 - link
The hypothetical 8% increase in peak performance seems like wishful thinking to me. The chart looks like "graphic design" marketing wank, not plotted data. I would only go by the printed numbers. That is, at an operating point that matches Skylake peak performance, Gracemont cores use less than 60% of Skylake's power, and if you ran Skylake at that same power, it would have less than 60% of Gracemont's performance.mode_13h - Thursday, August 19, 2021 - link
> I would only go by the printed numbers.Okay, so are those numbers you used hypothetical, or where did you see 60%?
Also, there's no fundamental reason why the ISO-power and ISO-performance deltas should match.