Hot Chips 2020: Marvell Details ThunderX3 CPUs - Up to 60 Cores Per Die, 96 Dual-Die in 2021
by Andrei Frumusanu on August 17, 2020 4:30 PM EST- Posted in
- Servers
- CPUs
- Marvell
- Arm
- Enterprise
- Enterprise CPUs
- ThunderX3

Today as part of HotChips 2020 we saw Marvell finally reveal some details on the microarchitecture of their new ThunderX3 server CPUs and core microarchitectures. The company had announced the existence of the new server and infrastructure processor back in March, and is now able to share more concrete specifications about how the in-house CPU design team promises to distinguish itself from the quickly growing competition that is the Arm server market.
We had reviewed the ThunderX2 back in 2018 – at the time still a Cavium product before the designs and teams were acquired by Marvell only a few months later that year. Ever since, the Arm server ecosystem has been jump-started by Arm’s Neoverse N1 CPU core and partner designs such as from Amazon (Graviton2) and Ampere (Altra), a quite different set of circumstances and alongside AMD’s successful return in the market, a very different landscape.
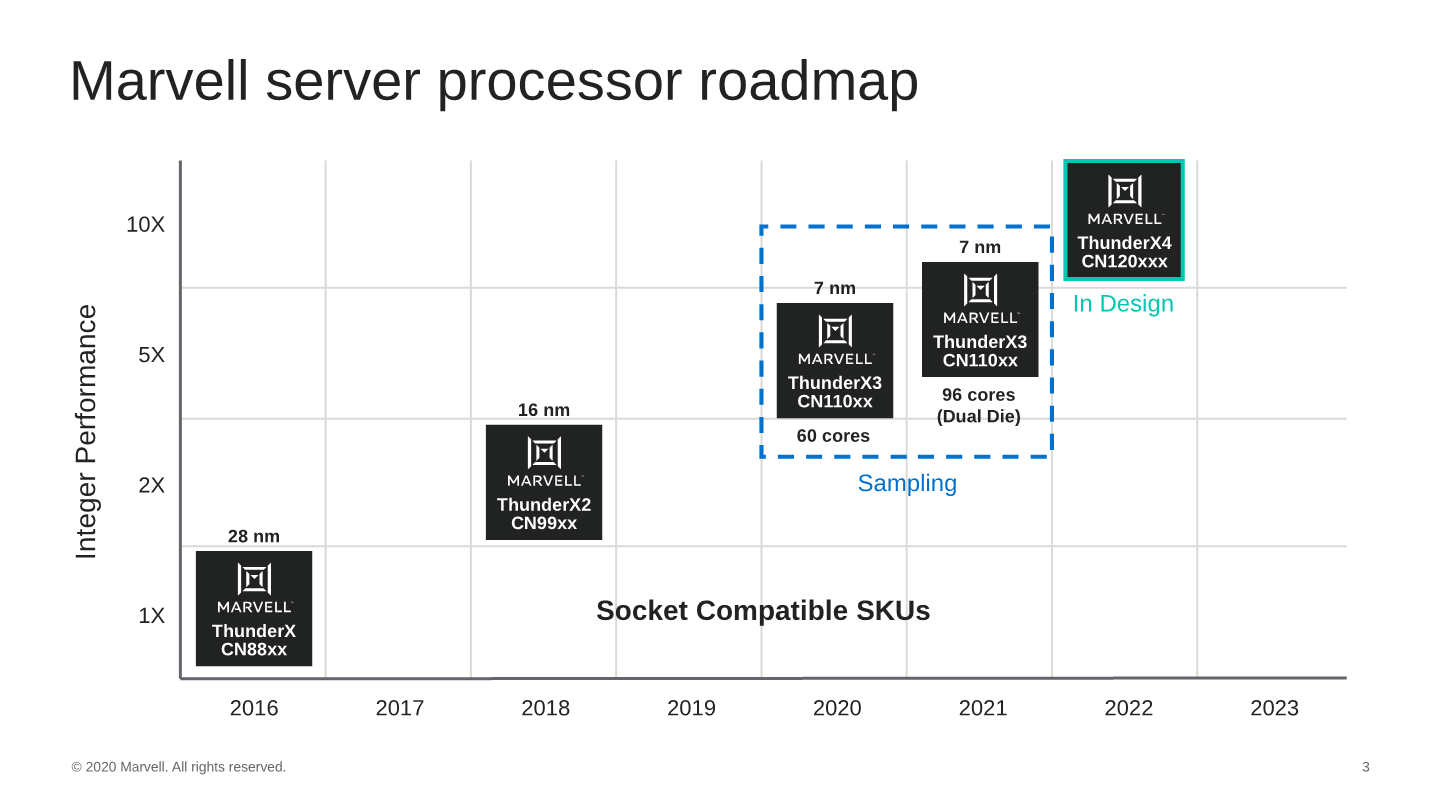
Marvell started off the HotChips presentation with a roadmap of its products, detailing that the ThunderX3 generation isn’t merely just a single design, but actually represents a flexible approach using multiple dies, with the first generation 60-core CN110xx SKUs using a single die as a monolithic design in 2020, and next year seeing the release of a 96-core dual-die variant aiming for higher performance.
The use of a dual-die approach like this is very interesting as it represents a mid-point between a completely monolithic design, and a chiplet approach from vendors such as AMD. Each die here is identical in the sense that it can be used independently as standalone products.
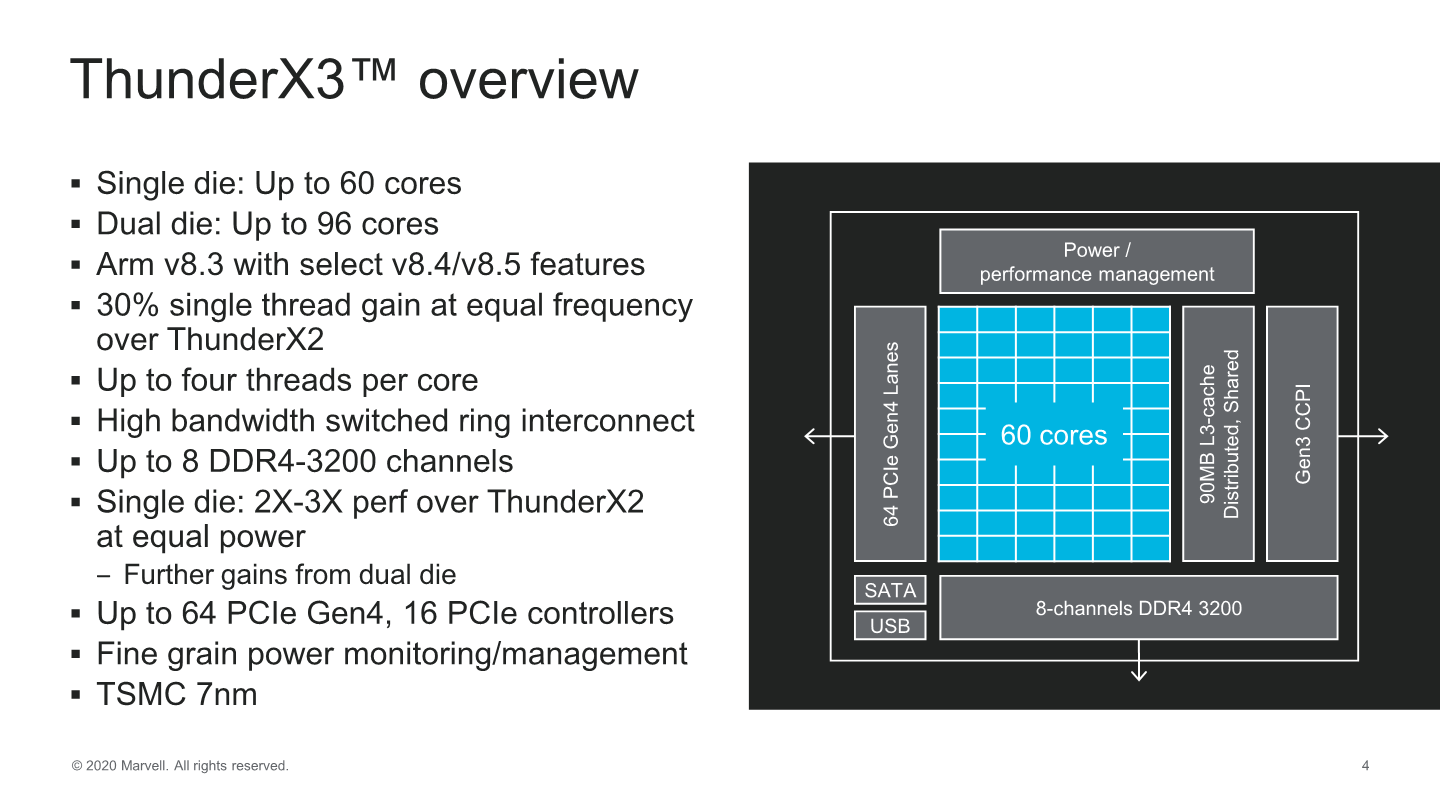
From a SoC-perspective, the ThunderX3 die scales up to 60 cores, with the 2-die variant scaling up to 96. The first thing question that comes to mind when seeing these figures is why the 2-die variant doesn’t scale up to the full 120-cores- Marvell didn’t cover this during the talk but there were a few clues in the presentation.
Marvell had made the performance improvement claim of 2-3x over a ThunderX2 at equal power levels. This latter had a TDP of 180W – if the TX3 maintains this thermal envelope then it would mean that a dual-die design would have had to grow TDPs to up to 360W which far beyond what one can air cool in a typical server form-factor and rack in terms of power density. Assuming just a linear cut-down to 96 cores as advertised we’d end up around 288W – which is more in line with the current high-end server CPU deployments without water-cooling. Of course – this is all our own analysis and take of the matter.
A single die supports 8 channels of DDR4-3200 which is standard for this generation of a server product and essentially in line with everybody else in the market. I/O wise, we see a disclosure of 64 lanes of PCIe 4.0 – which is again in line with competitors but half of what higher-end alternatives from Ampere or AMD can achieve.
One big unknown right now is how the dual-die product will segment the I/O and memory controllers – if this is going to be a 50-50 split in terms of resources between the two dies, or whether we’ll see an imbalanced setup – or if the platform can actually handle the full resources from each die and transform itself into a 16-channel 128 lane beast?
| Comparison of Major Arm Server CPUs | |||||
| Marvell ThunderX3 110xx |
Cavium ThunderX2 9980-2200 |
Ampere Altra Q80-33 |
Amazon Graviton2 |
||
| Process Technology | TSMC 7nm |
TSMC 16 nm |
TSMC 7 nm |
TSMC 7nm |
|
| Die Type | Monolithic or Dual-Die MCM |
Monolithic | Monolithic | Monolithic | |
| Micro-architecture | Triton | Vulcan | Neoverse N1 (Ares) | ||
| Cores | 60 (1 Die) Swiched 3x Ring 96 (2 Die) |
32 Ring bus |
80 Mesh |
64 Mesh |
|
| Threads | 240 (1 Die) 384 (2 Die) |
128 | 80 | 64 | |
| Max. number of sockets | 2 | 2 | 2 | 1 | |
| Base Frequency | ? | 2.2 GHz | - | - | |
| Turbo Frequency | 3.1 GHz | 2.5 GHz | 3.3 GHz | 2.5 GHz | |
| L3 Cache | 90MB | 32 MB | 32 MB | 32 MB | |
| DRAM | 8-Channel DDR4-3200 |
8-Channel DDR4-2667 |
8-Channel DDR4-3200 |
8-Channel DDR4-3200 |
|
| PCIe lanes | 4.0 x 64 (1 Die) |
3.0 x 56 | 4.0 x 128 | 4.0 x 64 | |
| TDP | ~180W (1 Die) (unconfirmed) |
180W | 250 W | ~110-130W (unconfirmed) |
|
On paper at least, the ThunderX3 seems quite similar to Amazon’s Graviton2 as they both share a similar amount of CPU cores and similar memory and IO configurations. The bigger differences that one can immediately point out to is that the ThunderX3 employs SMT4 in its CPU cores and thus supports up to 240 threads per die. There’s also a TDP difference, but I attribute this to the Graviton2 being conservative with its clock frequencies, whilst Ampere’s SKUs being more in line with the ThunderX3, particularly the 64-core 3.0GHz 180W Q64-30 being the closest match in specifications.
Another thing that stands out for the ThunderX3 is the 90MB of L3 cache that dwarfs the 32MB of the previous generation as well as the 32MB configurations of Ampere and Amazon.
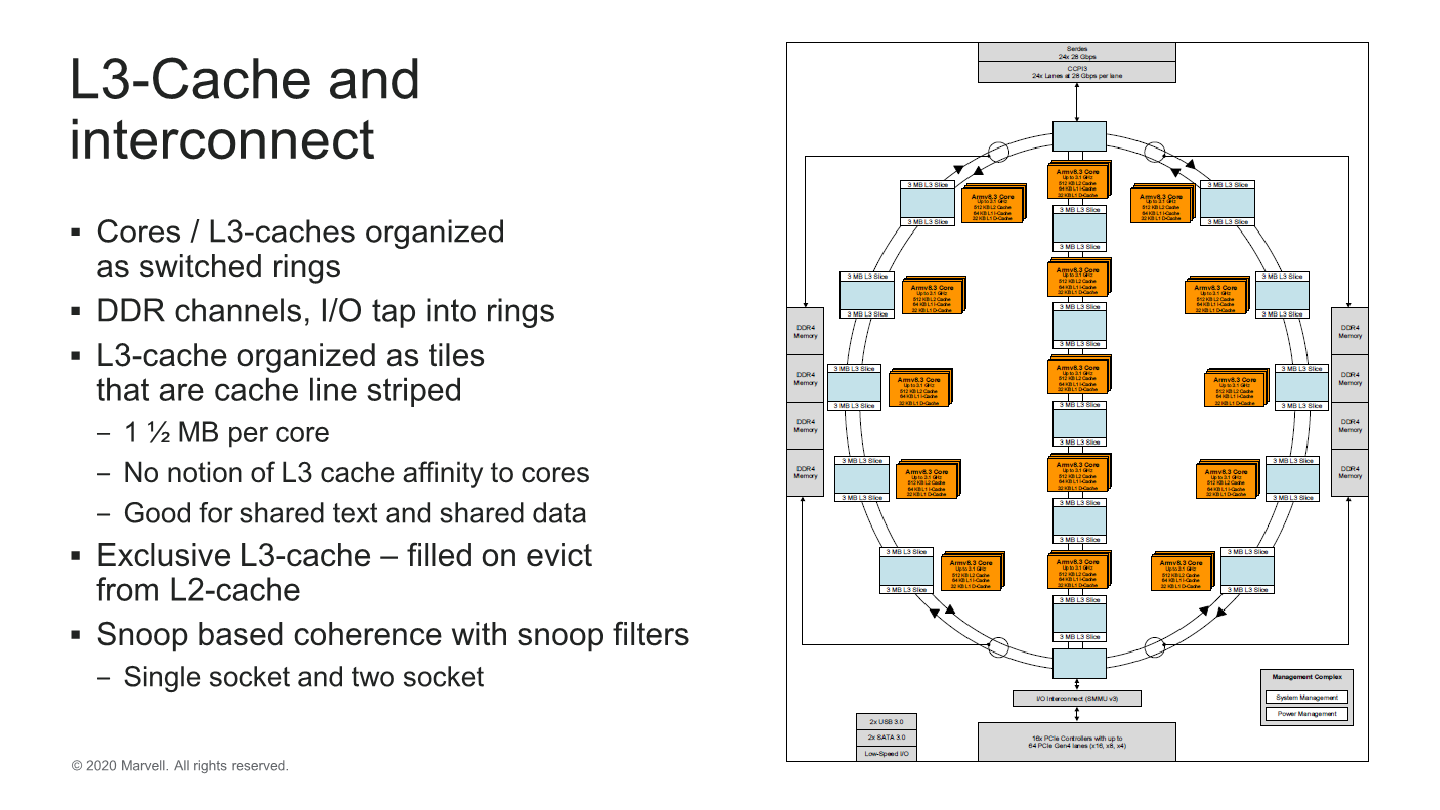
Marvell here opted to evolve its own interconnect microarchitecture which has now evolved from a simple ring design, to a switched ring with three sub-rings, or columns. Ring stops consist of CPU tiles with 4 cores and two L3-slices with 3MB of cache. This gives a full die with 15 ring stops (3x5 columns) and the full 60 cores 90MB of total L3 cache which is a quite respectable amount.
In the Q&A sessions, Marvell disclosed that their rationale for a switched ring topology versus a single ring, or a mesh design was that a single ring wouldn’t have been able to scale up in performance and bandwidth at higher core counts. A mesh design would have been a big change, and it would have required a reduction in core count. A switched ring represented a good trade-off between the two architectures. Indeed, if this is what enabled Marvell to include up to 3x the cache versus its nearest competitors, it seems to have been a good choice.
One odd thing I noted is that the system is still using a snoop-based coherency algorithm which comes in contrast with other directory-based systems in the industry. This might reduce implementation complexity and area, but might lag behind in terms of power efficiency and coherency traffic for the chip.
The memory controllers tap into the rings, and Marvell’s inter-socket/die CCPI3 interface here serves up to 84GB/s of bandwidth.








27 Comments
View All Comments
Spunjji - Wednesday, August 19, 2020 - link
Good to know your opinions on the future of the CPU market are just as balanced, nuanced and well-informed as your political ramblings...Quantumz0d - Wednesday, August 19, 2020 - link
Better go back to your twitter and reeesetera and put more pronouns.And you don't even have any argument, you are stuck on that political comment. And you will be stuck there forever.
Gomez Addams - Wednesday, August 19, 2020 - link
Your diatribe entirely missed the point of why people are moving to ARM-based processors for servers and other purposes. In can be summarized in two words : power consumption. Server farms can save a lot of money using ARM processors compared to the equivalent horsepower from just about any other processor available. They are not moving to them for any performance advantage.Wilco1 - Thursday, August 20, 2020 - link
Lower power also means less cooling, fewer power supplies and higher density. Additionally Arm servers need less silicon area to get the same performance, so upfront cost of server chips is lower too (you avoid paying extortionate prices like you do for many x86 server chips).eek2121 - Tuesday, August 18, 2020 - link
The x86 market is not shrinking. This server offers no benefits over a modern AMD or Intel server.name99 - Tuesday, August 18, 2020 - link
Two years ago you could reasonably have said "there is no plausible ARM server".A year ago you could legitimately have said "sure, there are ARM servers (TX2, Graviton) but they suck".
This year the best you can say is "they offer no benefit over a modern AMD or Intel server" (actually already not true if you're buying compute from AWS).
You want to bet against this trajectory?
Next year? This was the year of matching x86 along important dimensions. Next year will be the year of exceeding x86 along important dimensions. Not ALL dimensions, that might take till 2022 or so, (there's still a reasonable amount of foundational work to do by all parties, like implementing SVE/2) but, as I said, the trajectory is clear.
Spunjji - Wednesday, August 19, 2020 - link
I have to agree with this assessment. People keep counting ARM designs out because they've taken a long time to ramp up to this level, but every year they get closer to being a notable force in the market, and every year the naysayers find another, smaller reason to point to for they'll never be successful.The simple truth is that ARM designs don't even have to beat x86 to take a slice of the market - they just have to offer *something*, be it cost benefits, lower idle power, improved security, or even just being an in-house design (a-la Amazon).
Spunjji - Wednesday, August 19, 2020 - link
Your last statement doesn't follow from - or lead to - the first one.Spunjji - Wednesday, August 19, 2020 - link
Shrinking? Sure, eventually. Fast? Not so sure.AWS transitioning makes sense for their own use, but they'll more than likely need to continue offering x86 for customers. Same goes for Google and Microsoft. Hard to predict how that will shake out at this juncture.
Apple aren't even close to 10% of the total x86 market, either - they're between 7.5% and 8% of the global *PC* market, which obviously doesn't include the server / datacentre market. That's still going to be a bit of a dent for Intel when the transition completes, but it's not nearly as bad for x86 on the whole as you're implying.
Competition is heating up, though. That's a good thing.
Gomez Addams - Tuesday, August 18, 2020 - link
This illustrates why I think Nvidia wants to own Arm. They have already stated they are porting CUDA to the ARM instruction set. I think this is because they want to make a processor suited for HPC and it will be ARM-based and here's why. First, think of how their GPUs are organized. They use streaming multiprocessors with a whole bunch of little cores. These days they have 64 cores per SM so that is essentially 64-way SMT. The thing is these cores are very, very simple with many limitations. I think they want to use ARM-based cores with something like 16-way SMT. If they use AMD's multi-chip approach they could make an MCM with a thousand ARM cores in one package. There would be no CPU-GPU pairing as we often see today. One MCM could run the whole show. This would entirely eliminate the secondary data transfers to a co-processor and make for an incredibly fast super computer with relatively low power consumption. I think this architecture would be a huge improvement over what they have.