Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Memory Subsystem & Latency
Memory performance in server chips is absolutely crucial due to the sheer core count in the system. Amazon’s Graviton2 chip has the most modern memory capabilities of our test set thanks to 8 DDR4-3200 memory controllers, providing up to a theoretical 204GB/s peak bandwidth. What’s also important, is the SoC’s cache hierarchy and the latencies it’s able to access data at.
Looking at the linear latency graph results, let’s first focus on the DRAM region and see how the Graviton2 ends up relative to the competition.

Surprisingly enough, the Graviton2 does extremely well. Although the cache hierarchies between the designs are very different, when looking at an arbitrary 128MB memory depth, the three systems are near identical. We do see that the Graviton2’s full random latency increases at a higher rate the deeper into DRAM you compare it against the AMD and Intel systems. The structural memory latency between the Amazon and AMD chips are near identical, meaning the AMD system doing better further down in random accesses probably is due to better TLBs or page-table walkers.

Our measured 81ns structural estimate figure here almost directly matches up with Arm’s published 83ns figure from a year ago, further giving credence to Arm’s published figures from back then (Arm's figure was LMBench random using hugepages, we're accounting for TLB misses in our patterns with 4KB pages).
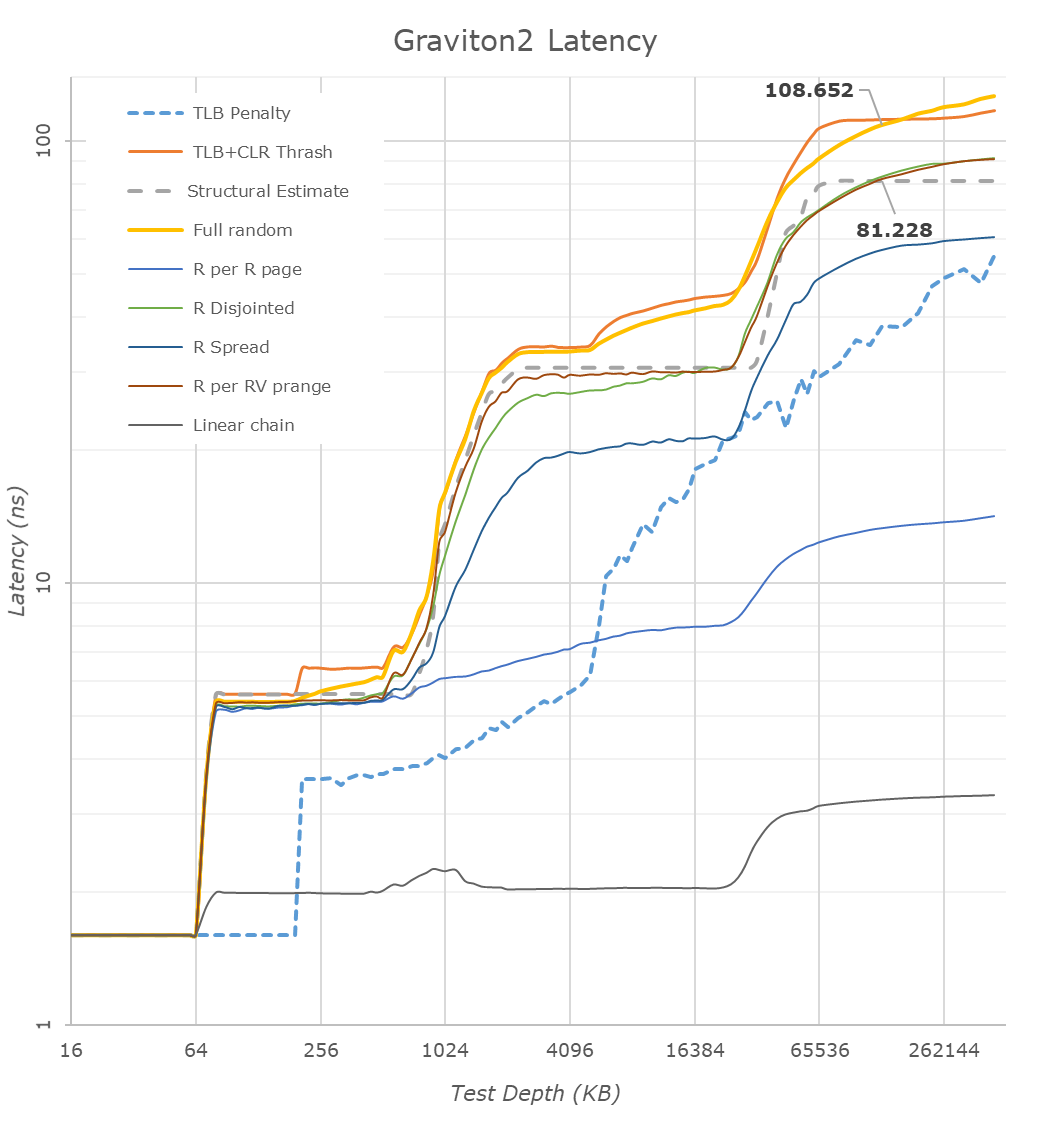
Turning to a logarithmical representation of the same data, we better see the difference in the cache hierarchy.
Compared to the AMD and Intel CPUs, we see the N1 cores’ advantage in the doubled 64KB L1D cache. Access latencies between the different cores should be 4 cycles, with the absolute figures in nanoseconds only differing due to the clock frequency differences between the cores.
The L2 cache of the Graviton2 falls in at 1MB and the access latency here is also competitive at 11 cycles. Arm gives the option between a 512KB 9 cycle or a 1MB 11 cycle configuration, and Amazon’s designers here chose the latter option. Halfway through the 1MB L2 cache we see the latencies of some access patterns increase, and this is due to the test exceeding the capacity of the L1 TLB which falls in at 48 pages (192KB coverage) for the N1 cores, also resulting in the big jump in the TLB miss penalty curve. AMD and Intel here go up to 64 pages and 256KB coverage. To be noted in these results is AMD’s prefetchers pulling into L2, whereas Arm and Intel cores only pull into L3 for more complex patterns.
Going beyond the L2, we reach the L3 where we’re able to test Arm’s CMN-600 mesh interconnect for the first time. The cache hierarchy covers 32MB depth; the interesting aspect here is that the latency remains relatively flat and within 2ns when testing some patterns between 3MB and 32MB, meaning there's fine-grained access hashing across the chip's slices.
The average estimate structural latency of the cache falls in at around 29.6ns, which isn’t all too great when compared to Intel’s ~18.9ns L3 cache, even considering that this is split up across 32 slices versus Intel’s 24 slices. Of course, AMD’s L3 leads here at only 10.6ns, but that’s only shared within 4 CPU cores and doesn’t go nearly as deep.
What we’re also seeing here is that the Graviton2’s N1 cores prefetchers aren’t set up to be nearly as aggressive in some more complex patterns than what we saw in its mobile Cortex-A76 siblings; it’s likely that this was done on purpose to avoid unnecessary memory traffic on the chip, as with 64 cores you’re going to be very bandwidth starved, and you don’t want to waste any of that on possible mis-prefetching.

Moving onto bandwidth testing, we’re solely looking at single-core bandwidth here.
Things are looking massively impressive for the Graviton2’s Neoverse N1 cores as a single CPU core is able to stream writes at up to 36GB/s. What interesting here is that the N1 cores like the Cortex-A76 cores here take advantage of the relaxed memory ordering of the Arm architecture to essentially behave the same as non-temporal writes would on an x86 system, and that’s why the bandwidth if flat across the whole test depth.
Loading from memory achieves up to 18.3GB/s and memory copy (flip test) achieves an impressive 29.57GB/s, which is more than double what’s achieved on the AMD system, and almost triple the Intel system. From a single-core perspective, it seems that the Arm design is able to have significantly better memory capabilities.
We’re still seeing the odd zig-zagging behaviour in the L1 and L2 caches for memory copies that we saw on mobile A76 based chips, possibly cache bank access conflicts for this particular test that showcase in Arm's new microarchitecture.
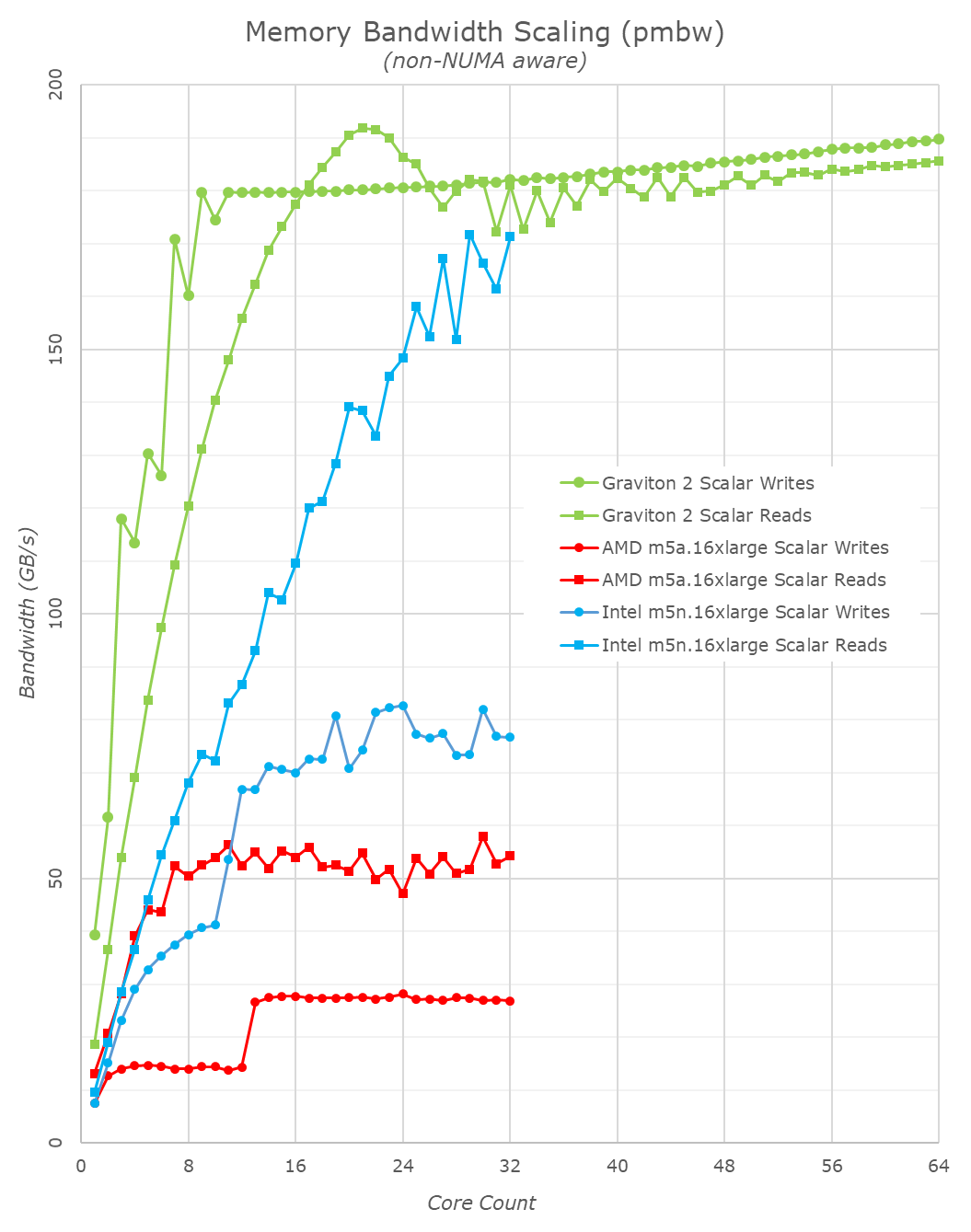
I didn’t have a proper good multi-core bandwidth test available in my toolset (going to have to write one), so fell back to Timo Bingmann’s PMBW test for some quick numbers on the memory bandwidth scaling of the Graviton2.
The AMD and Intel systems here aren’t quite representative as the test isn’t NUMA aware and that adds a bit of complexity to the matter – as mentioned, we’ll need to write a new custom tool that’s a bit more flexible and robust.
The Arm chip is quite impressive, and we only seemingly needed 8 CPU cores to saturate the write bandwidth of the system, and only 16 cores for the read bandwidth, with the highest figure reaching about 190GB/s, near the theoretical 204GB/s peak of the system, and this is only using scalar 64B accesses. Very impressive.








96 Comments
View All Comments
jbrower - Saturday, July 24, 2021 - link
Well at least you have a troll -- mark of success for authors, heheProDigit - Wednesday, March 11, 2020 - link
110W is very pessimistic, and would make no sense at all, considering that the ryzen 9 3900x uses 105W at 12 cores 24 threads at 4.6Ghz and 7nm, and the 3950 does the same with 4 more cores.Plus, regular arm based (AMLogic) boxes use 3Watt in total under load (that includes CPU+Ethernet+RAM+Emmc) for 4 CPU cores running at 1,9Ghz.
If you ask me, 64 core arm CPUs running at 2Ghz should run at around just over 1 watt per core, making it a 65W tdp chip
Andrei Frumusanu - Wednesday, March 11, 2020 - link
There's 64 PCIe4 lanes and 8 memory controllers in there as well.cdome - Wednesday, March 11, 2020 - link
Quick question. Does Graviton2 have support for SVE2 vector extension? if yes how wide are execution units? thank youAndrei Frumusanu - Wednesday, March 11, 2020 - link
No, there's 2x128b v8 ASIMD/NEON pipes.Soulkeeper - Wednesday, March 11, 2020 - link
What was used to generate the images on page 2 ?ie: https://images.anandtech.com/doci/15578/AMD-Epyc-6...
Is this app/source available to download ?
Thanks
sharath.naik - Wednesday, March 11, 2020 - link
Whats behind the name Annapurna? The name is Indian in origin but the company is Israeli.nijimon - Thursday, March 12, 2020 - link
Judging by the logo it could be referring to the massif in the Himalayas.https://en.wikipedia.org/wiki/Annapurna_Massif
Andy Chow - Thursday, March 12, 2020 - link
"I recently had the time to write a new custom microbenchmark for testing synchronisation latencies of CPU cores, exhibiting some of the cache-coherency as well as physical layouts of current designs."Wow, and what a benchmark that turned out to be. Please consider packaging it and releasing it. Or giving us the code so we can run it. I would really love to run that test on a few of my machines. I am frustrated with current benchmarks on this area also, and you seem to have built the perfect solution.
ballsystemlord - Thursday, March 12, 2020 - link
1 Grammar error:"Overall, it's a bit odd to see GCC ahead in that many workloads given that LLVM the is the primary compiler for billions of Arm devices in the mobile space."
Extra "the":
"Overall, it's a bit odd to see GCC ahead in that many workloads given that LLVM is the primary compiler for billions of Arm devices in the mobile space."