Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM EST
It seems like the new motto for Silicon Valley for the last few years has been “Data is the new oil,” and for good reason. The number of companies employing machine learning-based AI technologies has exploded, and even a few years after all of this has kicked off in earnest, those numbers continue to grow. This form of AI is no longer just an academic thesis or curious research project, but instead machine learning has become an important part of the enterprise market, and the impact on enterprise hardware – both purchasing and development – would be difficult to overstate. This is the era of AI.
At first sight, the hardware choices for these kinds of applications seem simple: Intel Xeon CPUs for storing and preprocessing data, NVIDIA GPUs for (almost) everything AI. And indeed, this has largely been case for the last few years now. However, NVIDIA’s competitors have not been standing idly by the entire time – and that especially goes for Intel, whose enterprise market share all of this ultimately threatens. With everything from dedicated low-power inference processors to purpose-optimized Xeons, Intel is taking aim at every level of the AI market. The net result is that between all of these competitors, we’re seeing AI tackled from many different directions, and the hardware battle for AI era is insanely interesting in our humble opinion.
Today we’re taking a look at what’s perhaps the heart of Intel’s hardware in the AI space, Intel’s second-generation Xeon Scalable processors, better known as "Cascade Lake". Introduced a bit earlier this year, these new processors are still based on the same core Skylake architecture as the first-generation products, but incorporate a number of new instructions to speed up AI performance.
And as far as new technology goes, this is certainly the most interesting aspect of Cascade Lake. While we could talk about the three to six percent general CPU performance improvement, the 56 cores of Intel’s most expensive processor ever, and the "world record benchmarks," these small improvements are close to irrelevant for the near and mid-term future of the IT world. Just look at the very first slide of the Intel press & analyst briefing.

Internet of things, data engineering, and AI. That is where a large part of the growth, the innovation, and the future of IT will be. And this is where Intel wants to be.
Right now, NVIDIA has a virtual monopoly on the “sexiest” part of this market, which is deep learning and “massively parallel HPC” software. Thanks to a confluence of factors on the hardware and software sides, most of this software is run on NVIDIA GPUs and clusters. So to the general public, it looks likes NVIDIA owns the “AI market”, a picture that is not inaccurate, but also not complete. There’s a lot more to the AI market than just neural network inferencing, and in particular, everything that has to happen to feed the AI model with data gets very little attention. As a result, it’s neural networks and Terminator robots that get all the headlines, even though they’re just part of the of the picture. In reality, the processing web for AI applications is much more like the picture below.
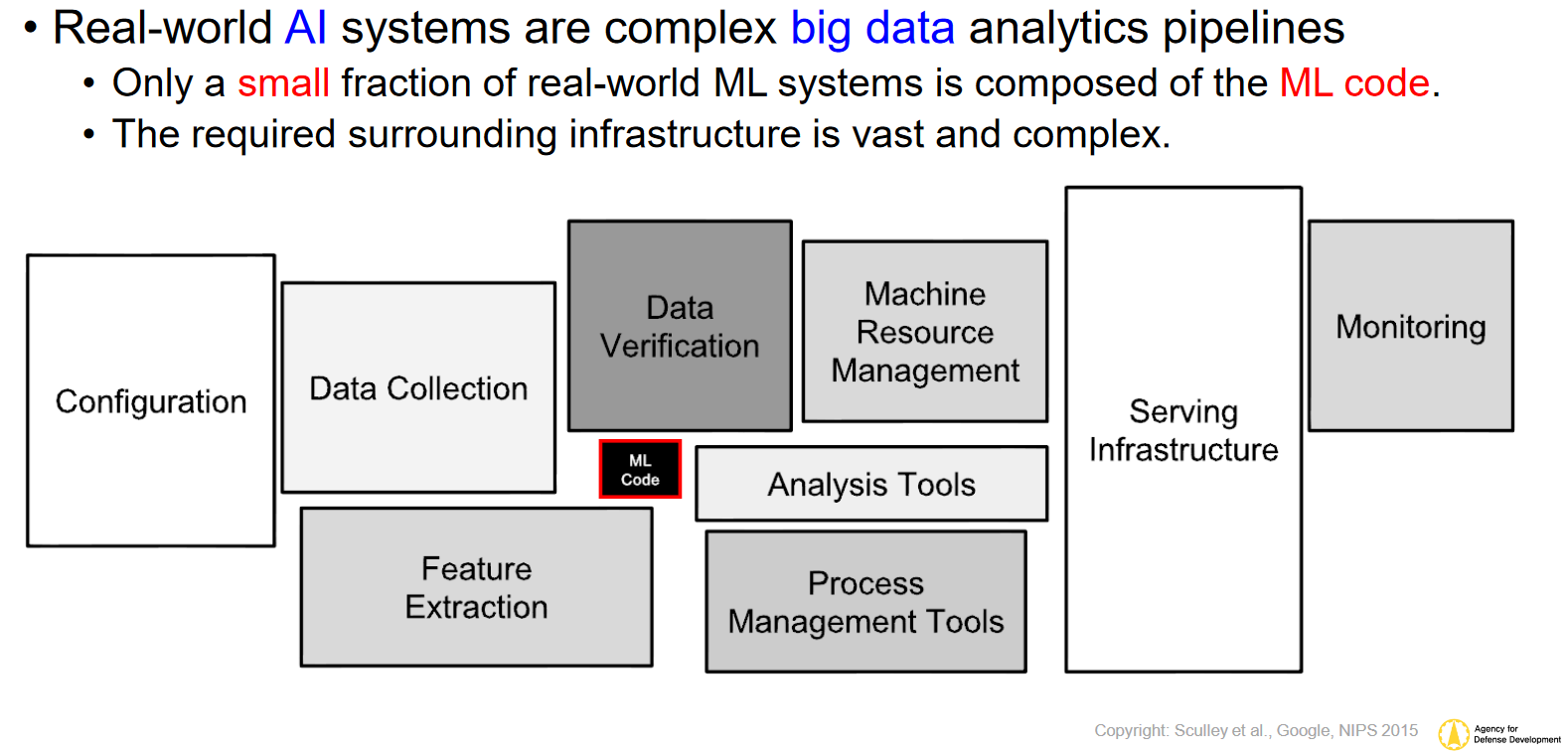
In short, actual machine learning code execution is only a very small part of the software tools necessary to build and AI Application.
Before you can even start, you have to ingest data, decompress, filter, reorder, map, and shuffle it around. Once everything is sorted and shuffled, you have to aggregate the data. As ML algorithms need large amounts of data to produce good predictions, that can be very processing memory intensive. Why? Let us delve a little deeper.








56 Comments
View All Comments
Bp_968 - Tuesday, July 30, 2019 - link
Oh no, not 8 million, 8 *billion* (for the 8180 xeon), and 19.2 *billion* for the last gen AMD 32 core epyc! I don't think they have released much info on the new epyc yet buy its safe to assume its going to be 36-40 billion! (I dont know how many transistors are used in the I/O controller).And like you said, the connections are crazy! The xeon has a 5903 BGA connection so it doesn't even socket, its soldered to the board.
ozzuneoj86 - Sunday, August 4, 2019 - link
Doh! Thanks for correcting the typo!Yes, 8 BILLION... it's incredible! It's even more difficult to fathom that these things, with billions of "things" in such a small area are nowhere near as complex or versatile as a similarly sized living organism.
s.yu - Sunday, August 4, 2019 - link
Well the current magnetic storage is far from the storage density of DNA, in this sense.FunBunny2 - Monday, July 29, 2019 - link
"As a single SQL query is nowhere near as parallel as Neural Networks – in many cases they are 100% sequential "hogwash. SQL, or rather the RM which it purports to implement, is embarrassingly parallel; these are set operations which care not a fig for order. the folks who write SQL engines, OTOH, are still stuck in C land. with SSD seq processing so much faster than HDD, app developers are reverting to 60s tape processing methods. good for them.
bobhumplick - Tuesday, July 30, 2019 - link
so cpus will become more gpu like and gpus will become more cpu like. you got your avx in my cuda core. no, you got your cuda core in my avx......mmmmmmbobhumplick - Tuesday, July 30, 2019 - link
intel need to get those gpus out quickAmiba Gelos - Tuesday, July 30, 2019 - link
LSTM in 2019?At least try GRU or transformer instead.
LSTM is notorious for its non-parallelizablity, skewing the result toward cpu.
Rudde - Tuesday, July 30, 2019 - link
I believe that's why they benchmarked LSTM. They benchmarked gpu stronghold CNNs to show great gpu performance and benchmarked LSTM to show great cpu performance.Amiba Gelos - Tuesday, July 30, 2019 - link
Recommendation pipeline already demonstrates the necessity of good cpus for ML.Imho benching LSTM to showcase cpu perf is misleading. It is slow, performing equally or worse than alts, and got replaced by transformer and cnn in NMT and NLP.
Heck why not wavenet? That's real world app.
I bet cpu would perform even "better" lol.
facetimeforpcappp - Tuesday, July 30, 2019 - link
A welcome will show up on their screen which they have to acknowledge to make a call.So there you go; Mac to PC, PC to iPhone, iPad to PC or PC to iPod, the alternatives are various, you need to pick one that suits your needs. Facetime has magnificent video calling quality than other best video calling applications.
https://facetimeforpcapp.com/